关于2篇基于GAN网络的对抗攻击算法论文的笔记
AI-GAN
发表去向
发表于21年IEEE ICIP
创新点总结
Attack-Inspired GAN在原始的GAN生成网络的基础上引入了额外的对抗器(attacker)加入到GAN网络的训练过程中, 使原有的生成模型可以高效地生成针对特定图像和特定类别的扰动矩阵, 即实现有目标攻击(target attack). 对于已有的利用GAN的对抗算法, 常常存在以下问题: 生成能力受限, 每次推理只能生成实现一种特定类别的攻击, 对于不同类别需要重复训练; 难以泛化到真实世界数据集中(测试的数据集局限在MNIST或CIFAR). 针对上述算法局限, AI-GAN实现了以下创新:
- 改进GAN网络结构, 在传统的生成器G-判别器D结构外引入了攻击器Attacker, 三者同时训练
- 提升了对抗样本在更接近现实场景分布的数据集中的攻击效果
- 展现了一定的迁移性, 同时优于经典对抗算法
算法内容
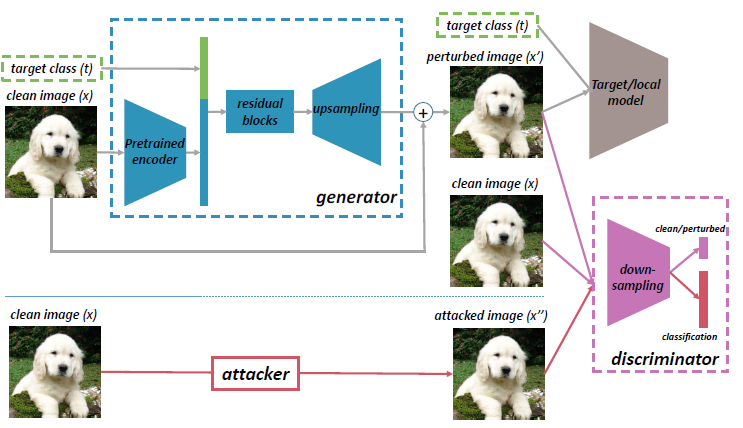
AI-GAN的整体架构如上图所示. 其中的判别器D被设计为双头判别器(可以理解为有两个分类器对应多个输入), 生成器G负责生成针对特定类别的扰动矩阵, 需要输入原始图像和目标攻击类别. 对于判别器, 除了干净图像和由生成器G获取的对抗样本外, 还会额外输入由攻击器A生成的另一个对抗样本, 文中A被设定为PGD算法. 因此在训练过程中, 判别器不仅需要判断输入图像是真实图像还是扰动后的图像, 还需要额外对扰动图像的来源进行分类.
对于判别器G的具体设置, 其包含了两个分支(branches), 其中一个被用来分辨干净图像和扰动图像, 另一个用来分辨扰动图像是由G产生还是由A产生. 此外, 为了提高生成器G的对抗性能, 作者还加入了对抗训练的流程. 此外, 设计上述的鲁棒的判别器D还可以帮助训练过程的稳定和加速收敛. 最终, 判别器D的损失函数包含了以下部分: 针对干净-扰动图像分类的$\mathcal{L}_S$, 针对扰动图像来源分类的$\mathcal{L}_{C}$, 完整的表达形式如下:
上式中的y指输入图像的真实类别, 训练过程中判别器的优化目标是最大化上述损失函数.
对于生成器, 作者从提升其可拓展性(scalability)的角度出发, 提出了通过自监督方式对编码器进行预训练的方法(但论文中并未明确说明实现过程). 预训练编码器使模型近似于在特征空间进行扰动攻击, 某种方式上提升了对抗样本呢的迁移性, 此外额外引入的多头判别器D也使生成器G的对抗性能得到进一步的提升. 对于生成器G的损失函数, 包括以下部分: 度量对目标模型攻击效果的$\mathcal{L}_{target(adv)}$ , 对于判别器的攻击损失$\mathcal{L}_{D(adv)}$, 以及上述判别器D中的损失函数项$\mathcal{L}_{S}$, 具体的数学表达形式如下:
上式中的t为对抗目标类别, $C_i$代表不同分类器的分类结果, 优化目标是最大化损失函数.
实验结果
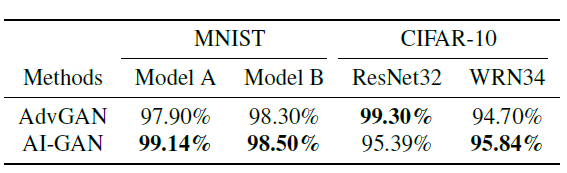
模型主要比较了自身算法与较早提出的基于GAN的对抗攻击算法AdvGAN之间的攻击效果的差异(比较的方法较少), 仍然是在MNIST和CIFAR-10数据集上的实验结果如下.
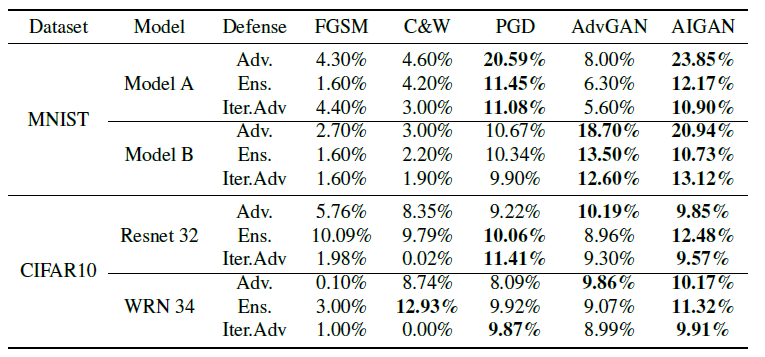
此外, 作者在对抗防御场景下将AI-GAN与众多经典算法进行了比较, 该场景的设置背景为使用对抗样本混合原始样本进行对抗训练, 该过程中的对抗训练的样本来源于FGSM和PGD等算法. 在AI-GAN的训练过程中由于需要用到待攻击目标模型进行G的训练, 在训练过程中则不加入对抗训练流程, 最终的实验结果如下. 可以看出在施加了对抗防御的背景下模型的攻击性能即使仍是最优也出现了明显的下降, 且作者标注了前二好的算法结果来夸大AI-GAN的SOTA性质.
最后作者就可拓展性的问题进行了专门的实验, 其实质就是在更复杂的CIFAR-100数据集上进行了简单验证, 仅就AI-GAN的实验结果而言, 在白盒攻击场景下仍然实现了87.76%的ASR.
论文总结
论文里出现了较多定义不清和表述模糊的地方, 实验开展和性能比较部分也不够完备, 但在攻击角度下的GAN结构的改进, 尤其是额外的攻击器的引入, 仍有较强的启发性.
Meta-GAN attack
发表去向
由2021年iccv拓展而来, 发表于IEEE TIFS, 论文原题为Robust and Generalized Physical Adversarial Attacks via Meta-GAN
创新点总结
为实现数字域对抗样本图像在真实物理场景下的有效性, 当前的物理对抗攻击算法往往关注对各种物理变化的模拟并将其融合进对抗样本的生成过程, 然而这种方式往往较大的人力成本来针对新的数据和模型模拟物理变化, 同时算法迭代优化对抗扰动时的时间开销较大. 针对上述局限, 论文提出了一种鲁棒和可泛化的物理域对抗攻击算法, 名为Meta-GAN Attack, 通过GAN模型的引入, 该算法不仅能够生成可物理部署的对抗样本, 还融合了元学习的思想, 使模型在攻击未知的模型目标时仅仅通过少量的数字和物理图像实现攻击性能的泛化, 可以实现类别无关和模型无关(class-agnostic and model-agnostic)的元学习效果. 具体创新点总结如下:
- 基于GAN模型完成D2P中的图像颜色与色彩失真的模拟过程, 生成物理可部署的对抗样本. 另外引入额外的CycleGAN网络实现数字图像到物理重采集图像的转换过程, 提升了算法的class-agnostic能力(难以获得未知数据集的真实物理图像)
- 定义class-agnostic and model-agnostic的few-shot场景, 设计了对应的meta learning算法(CMML)提升GAN网络的未知场景泛化性能
- 在两个不同数据集下开展了较为完备的验证实验
算法主要内容
算法背景
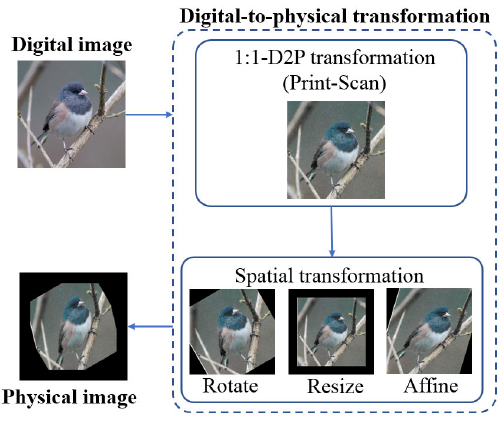
本文所定义的物理域攻击场景主要是指数字域对抗样本生成-打印-相机重采集-部署攻击的流程, 如下图流程所示. 这种打印-重采集的顺序变换被称为digital-to-physical(D2P) transformation.

由于相机与目标间的距离变化, 视角变化和打印材质的特征变化等因素, 物理域攻击往往比数字域攻击更不可控. 上述D2P的过程的核心是为重采集后的数字图像引入色彩和形状失真(distortion). 为了使对抗样本在D2P后仍能保持对抗性能, 物理域对抗算法往往在样本迭代过程中加入对D2P的模拟操作.
然而, 面对实际部署过程中可能出现的模型未知与获取的目标图像数据集的类别和每类图像的数量都受限, 因此该场景的攻击可以被定义为few-shot的攻击场景, 通过meta learning算法的引入可以使已被完整训练的模型和算法参数在较小数据量的基础上通过少数轮次的训练即可实现较为理想的攻击效果.
特别地, 对于D2P的转换过程, 作者根据不同的情况进行可能的失真原因的分解(失真可能使多种原因叠加导致的), 包括1:1 D2P, 意为重采集图像和原始数字图像间为大小等比关系, 没有发生形状上的改变, 但可能由于打印设备/采集设备的原因造成像素值的失真; 空间形变(Spacial Transformation), 即由于相对位置和视角变化导致的图像形变. 对于上述变化情况, 相应的示意图如下.
结构设计与算法核心
算法的核心架构为用于生成对抗扰动的GAN网络, 其中的生成器G会在生成对抗图像的同时模拟D2P过程中的颜色和形状失真. 对于元学习部分, 可以理解为在训练完成的GAN模型基础上利用少数新数据集的数据进行微调, 继而实现攻击性能的泛化. 对于GAN模型的损失函数设计部分, 论文从三个角度展开:
- 满足数字域图像攻击
- 对1:1 D2P鲁棒
- 对Spacial Transformation鲁棒
对于第一部分, 优化的目标函数如下. 式中的$\mathcal{L}_{adv}$是待攻击目标模型的交叉熵损失, $f$为对应分类模型, $y_t$为指定攻击类别.
对于第二部分, 论文指出可以通过引导数字域的对抗样本与重采集后的物理图像的相似程度实现对1:1 D2P的鲁棒性, 因此可以将GAN作为域迁移的手段(从数字图像$\chi_d$到物理图像$\chi_p$), 对应的GAN网络损失函数如下, 式中的$D$为判别器, $G$为生成器.
对于第三部分, 受EOT方法的启发, 论文引入了多个空间变换函数, 如旋转, 平移, 缩放和仿射变换等($t \in T$)来模拟物理场景下的形状失真, 然后基于一系列合成的伪变化图像进行训练来提升对空间变化失真的鲁棒性, 对应的优化方程如下(融合入式(1)):
特别的, 对于上述不同类型的函数t的构造, 都可以通过参数可变的统一齐次变换矩阵实现(不同的变换效果对应不同的参数), 统一后的变换表达式如下:
将EOT过程转换为上述的统一齐次变换表达形式的好处是确保了函数$t$的可导性质(变换本身是一种线性组合), 方便后续将图像矩阵作为自变量的梯度求解过程. 综合上述各部分损失函数, 最终的GAN网络损失函数表达形式如下:
上式中的最后一项距离度量是为了限制对抗样本的形变幅度, 保持其视觉上的不可感知性.
基于上述损失函数的说明, 在训练过程中需要有足够的数字域图像和物理域图像构成的图像对来完成对GAN网络的训练, 而针对元学习的场景, 对于未知任务下的数据集, 需要为各个类别手动构造few-shot的图像对. 论文里元学习场景下的class-agnostic and model-agnostic可以理解为用于生成对抗样本的Attack GAN面对不同的任务$\tau_i$, 每个任务都由用于微调训练的少量样本数据集$D_s$, 用于测试生成对抗样本性能的测试数据集$D_q$和待攻击的目标分类器$f$, 不同任务之间上述变量各不相同. 从多个任务的宏观视角出发, 设定共有n个任务, 其中的n-1个任务都可以用于Attack GAN的微调, 最后一项任务作为彻底的测试项. 在该场景下的Attacker GAN的更新流程如下:
首先在单个任务$\tau$上微调Attack GAN中的G和D
然后将所有任务的损失项求和作为总的meta损失, 表达形式如下:
然后对Attack GAN的整体进行参数更新的数学表达形式如下:
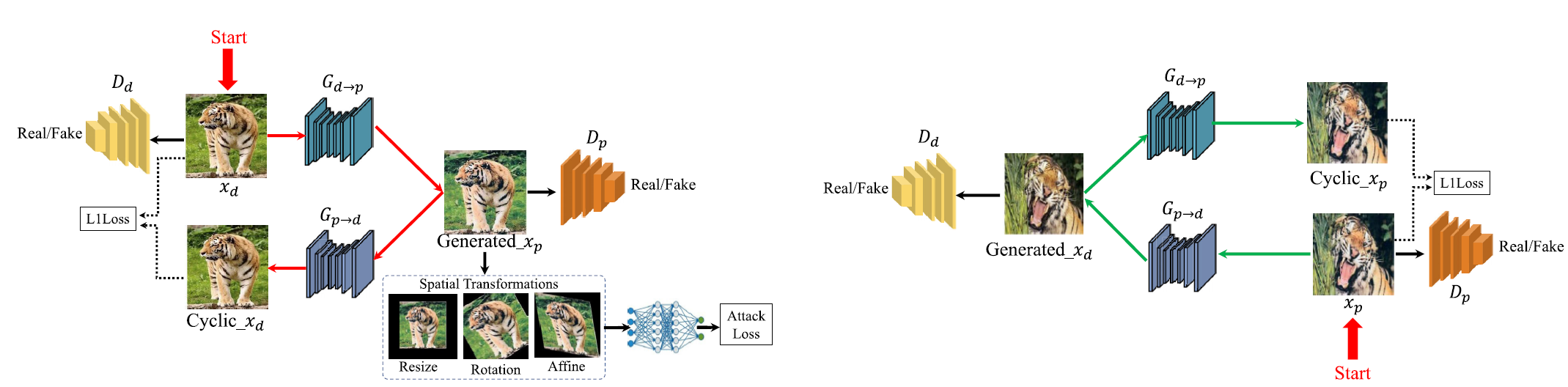
在上述场景中还存在另外的较为显著的限制, 即在各个任务的$D_s$中物理图像和数字图像不完全成对或由于获取难度的限制用于训练的物理图像的数量会显著少于真实图像. 为解决对应问题, 论文引入了额外的Cycle GAN作为数字图像到物理图像的域转换器, 应用流程如上图所示. 根据Cycle GAN的定义, 其模型中会包含两个生成器G和两个判别器D, 其结构的特征的通过循环迭代的方式来避免严格成对的训练数据的依赖, 相应的损失函数的表达形式如下:
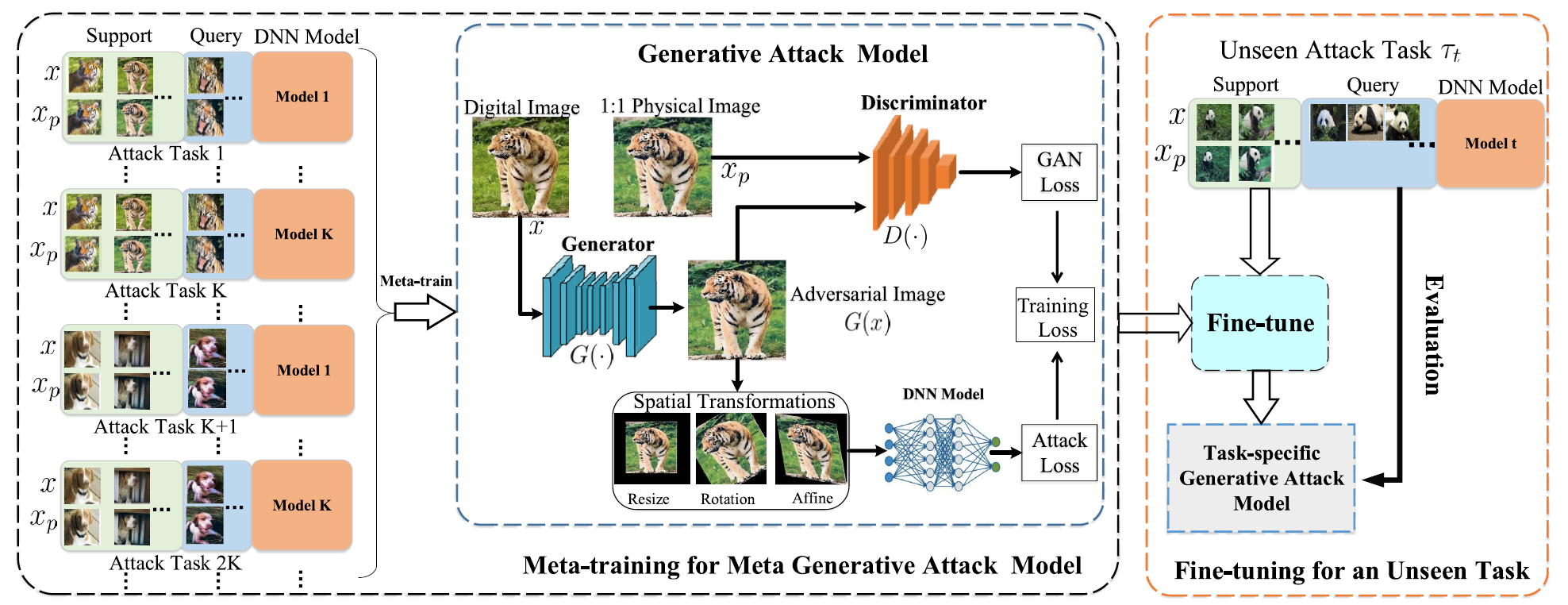
对于该额外框架内的应用在文中没有非常清晰的说明, 可以理解为对不同任务下的$D_s$的数据补齐, 最后, 全文的算法框架如下图所示:
实验设计与验证结果
本文在实验部分设计了四个对照实验, 使用的数据集为ImageNet和GTSRB(German Traffic Sign Recognition Benchmark)
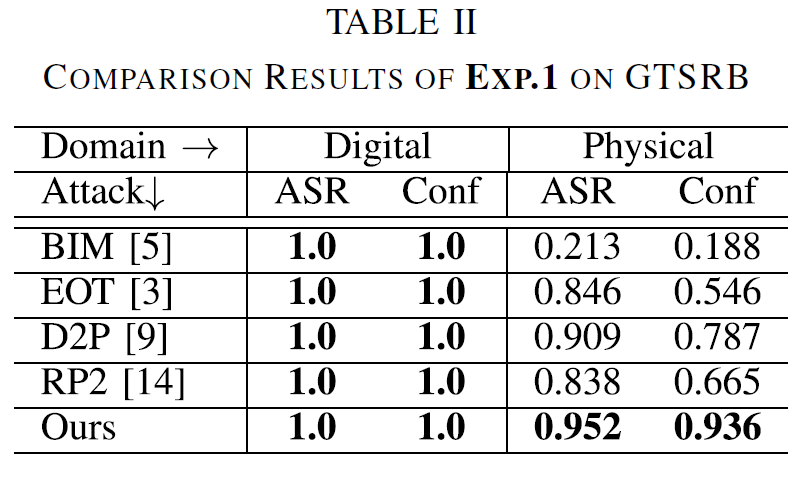
实验1为在白盒场景下攻击所有数据可获取的数据集和目标模型, 相应的实验结果如下.
实验2,3分别为在已知模型和未知数据以及未知模型和已知数据上进行了相应测试, 此处不再赘述. 实验4为未知模型和未知数据上的测试, 对应结果如下图所示.
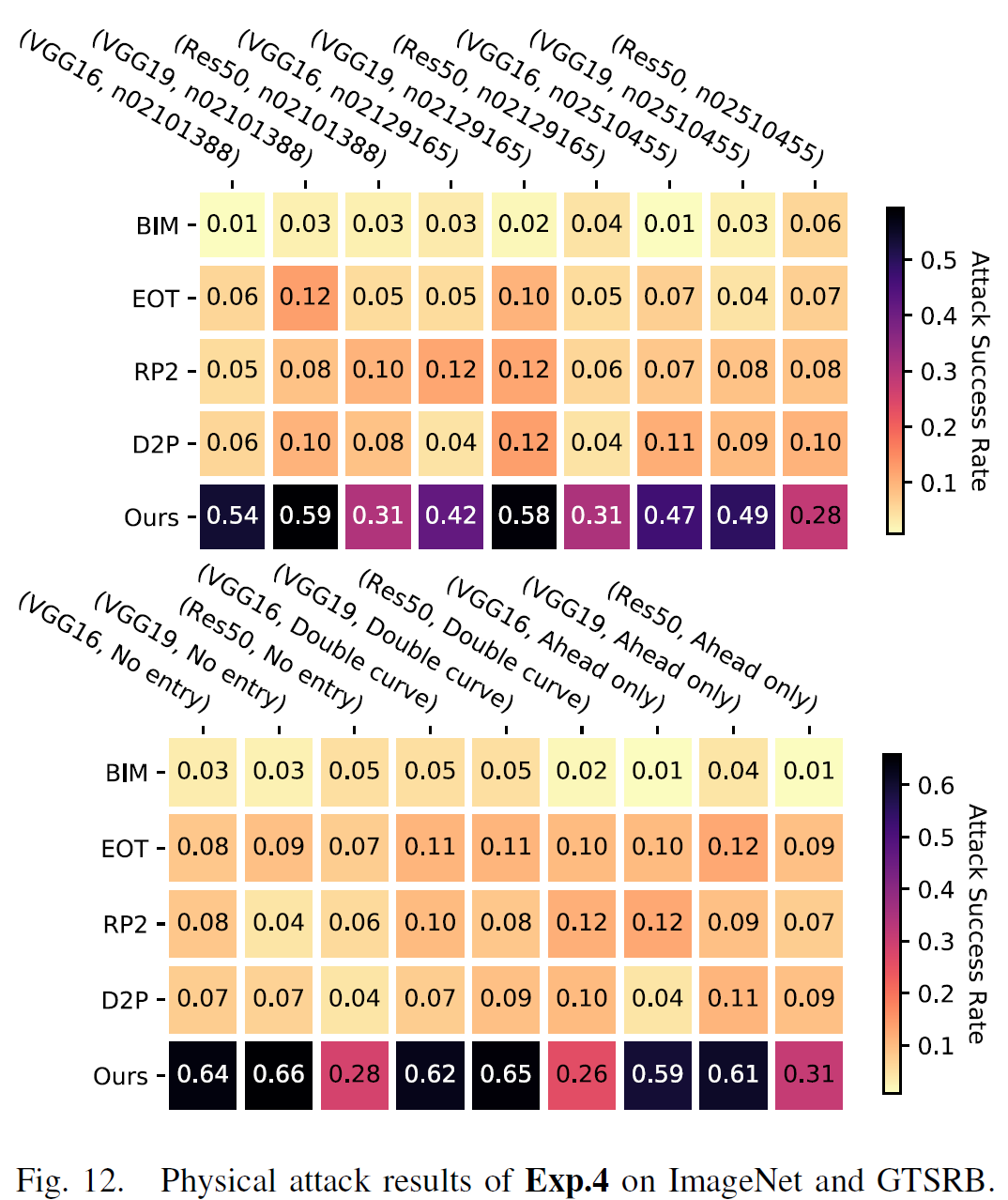
总结
Meta-GAN融合了GAN网络和物理攻击场景, 同时加入了meta learning的相应概念, 其中利用多个GAN模型分别进行对抗样本生成和不同分布下的图像域转换的思路也可以融合到SAR图像的仿真-实测的图像域转换场景中.