关于结合LT分布与AT(Adversarial Training)的论文笔记
发表情况
2021年CVPR oral论文
摘要与创新点总结
对抗样本的提出解释了CNN架构为代表的神经网络模型具有特殊的脆弱性, 而对抗鲁棒性则重点关注提升模型对对抗样本的识别准确率, 使模型在处于攻击的场景下仍能保持性能, 同时拓展对模型性能的评估角度, 进一步解释神经网络模型的内在机理. 然而, 从数据角度出发, 大部分模型训练所用数据均是均匀分布的, 而在现实场景中数据的分布常为长尾分布(Long-tailed Distribution). 在论文中, 作者从长尾分布数据的角度出发, 揭示了该数据分布对模型的识别性能和对抗鲁棒性造成的负面影响. 在此基础上, 作者提出了针对长尾分布数据集的高效对抗训练框架(可以理解为defense手段), 实现了该场景下的SOTA效果. 对于论文的场景, 作者定义了两种识别准确率 $A_{nat}$ 和 $A_{rob}$ , 前者指natural, 会在默认训练和加入对抗训练的两种模型上进行评估, 而后者指robust, 仅在对抗训练的分类模型上进行评估. 对于二者的区别, 可以用如下公式表示.
上式中的$R_{bdy}$指那些干净和被正确分类的输入的features与决策边界的$\epsilon$范围的距离. 为了使$A_{nat}$较大且$A_{rob}$较小, 作者认为可以从长尾分布数据再平衡的角度着手. 综上, 本文的创新点可总结如下:
- 首次提出从数据长尾分布的角度研究模型对抗鲁棒性的问题
- 结合针对长尾分布的rebalance方法和对抗训练方法
- 提出了SOTA的针对长尾分布的对抗鲁棒训练框架
核心方法
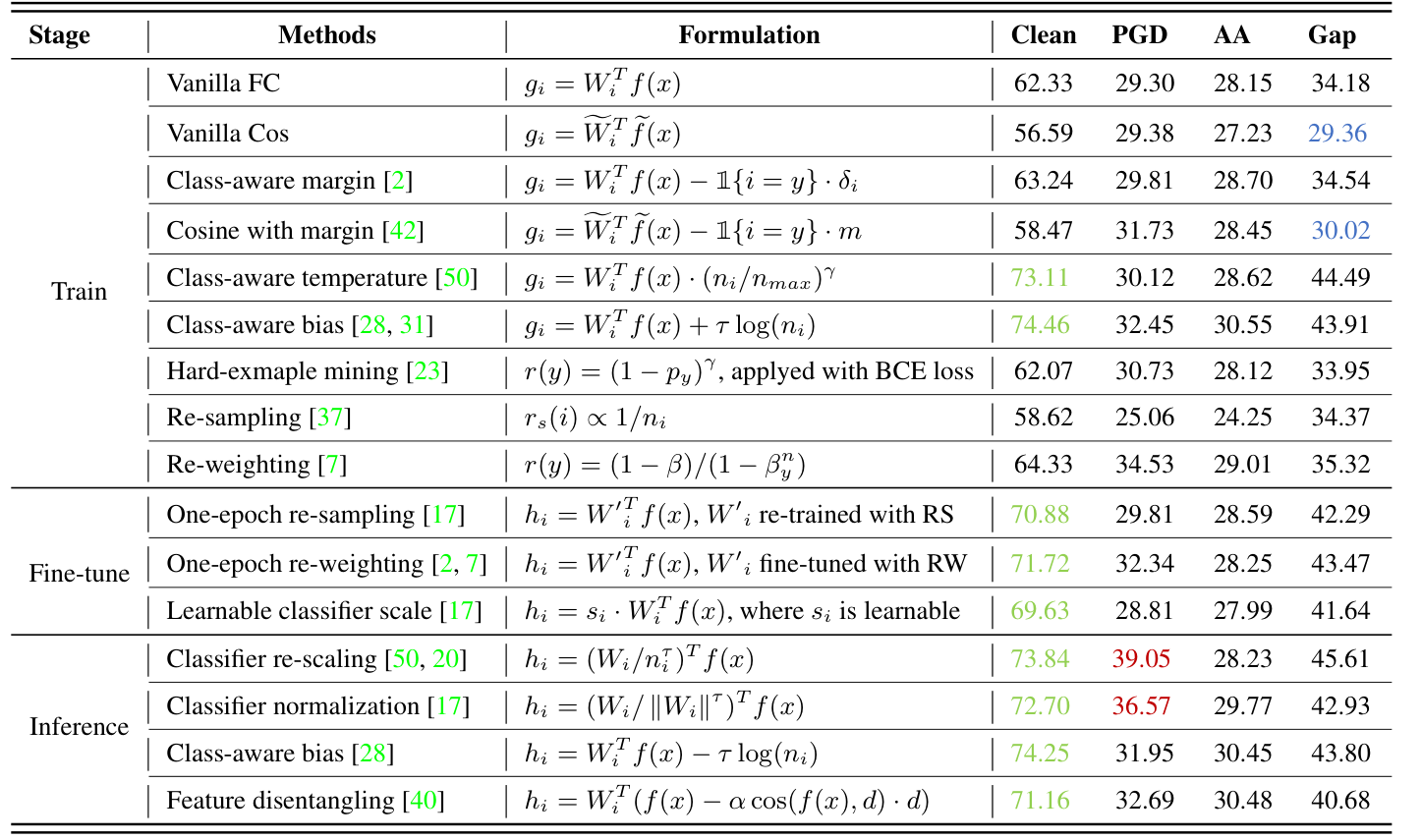
现有方法及其实验结果分析
首先需要对Adversarial Robustness的定义进行阐释, 该定义主要指通过Adversarial Defence或Adversarial Training(AT)的方法提升模型在受到对抗样本攻击时的分类性能. 针对LT策略和AT框架结合后对模型的影响, 作者进行了详尽的实验, 结果如下:
对于对抗训练的流程, 可以用如下数学形式表示:
上式中的内部优化目标时找到最有效的对抗扰动, 外部目标是通过损失函数的梯度下降使模型对对抗样本也保持鲁棒性. 两个损失函数都可以用CE损失. 而对于LT分布下的模型优化方法, 可以大致分为三类: training, fine-tuning和inference. 同时对以下表达进行规定: $f(x)$为图像$x$输入模型后提取深层特征向量, $W$为分类器的权重向量; $\tilde{f}(x)$ 和 $\tilde{W}$ 则为对上述向量进行归一化后的结果.
在训练结果, 作者结合多种针对长尾分布的重采样和代价敏感学习(cost-sensitive learning)的方法, 提出了改进的基于CE的损失函数, 具体数学表达形式如下:
上式中的$g(\cdot)$代表分类模型进行softmax前的logit值, $r_w(y)$则代表对于类别y的re-weighting因子, 相当于对这类样本的采样频率. $g$函数由多种表达形式, 常用线性分类形式:
此外, $L’_{CE}$还可用于加入到对抗训练中(即模型更新所用梯度和对抗样本生成所有梯度均来自作为标量的$L’_{CE}$损失函数). 在fine-tuning阶段, 核心的做法是将模型的backbone冻结, 通过数据re-balancing的技术对模型进行微调, 实验结果表明经过一轮微调即可显著提升$A_{nat}$, 但后续微调轮次增加的效果则不明显. 在inference阶段, 作者比较了权重正则化($\tau-norm$), classifier re-scaling 和 feature disentangling等解决LT问题的算法. 结果均已在上述表格中.
在实验中作者发现, 当前的LT methods对于$A_{nat}$ 和 $A_{rob}$ 间性能存在差距的问题都没有较好的解决手段. 然而, cosine classifier相较于传统的linear classifier则在这个问题上有更好的表现. 对于linear classifier, 可以简单理解为通过CNN提取出特征向量后, 在执行分类层时近似为线性运算, 进而获得模型输出的logits, 相应的表达形式如下:
上式中f(x)表示CNN模型的backbone, $z_j$表示第j类的logits值. 而在cosine classifier中, 对特征向量$f(x)$ 和 对应权重$W_j$进行归一化操作, 这样两者的点乘结果即为两向量间的余弦值, 因此避免了向量长度对预测分类结果的影响, 提高对LT分布数据集的分类鲁棒性.
RoBal训练框架
结合上述实验结果, 作者总结了长尾分布下的对抗鲁棒性面临着两个主要问题:
- 合适的特征向量与嵌入手段的选择
- 如何更好地将LT方法与AT对抗训练框架相结合
针对以上两个问题, 作者提出了包含尺度不变分类器(scale-invariant classifier)和二阶段再平衡(re-balancing)的Robust and Balanced训练框架, 即RoBal.
scale invariant classifier
经典的线性分类器的logit计算可以写为如下的数学形式:
针对其中的$W$项作者进行了尺度不变的思路延申. 在AT的框架下, 最初可以被正确分类的样本可以根据是否产生有效的对抗样本而分为两类. 通过计算scaling ratio(如下式(7)所示), 可以观察这两类不同图像的分布情况, 结果表明可以产生有效对抗样本的类别有更高的scaling ratio.
对于不同类别的scaling ratio分布如下图所示, 由上至下分别是原始样本和加入扰动后的对抗样本的scaling ratio和图像数目的分布情况:
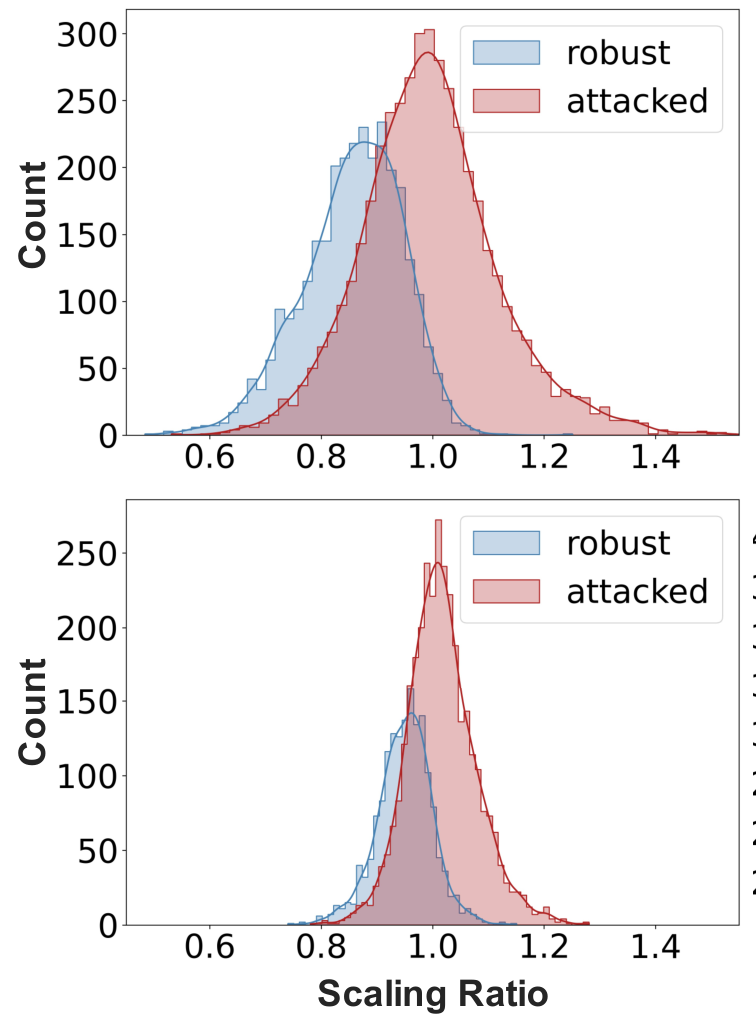
对于尺度不变的自然想法就是引入cosine classifier, 降低权重向量和特征向量的模长对分类的影响.
two-stage re-balancing
在从AT的角度出发引入cosine classifier后, 针对训练数据的长尾分布, 作者对$cos\theta_i$ 和 $b_i$这两个变量提出了对应的改进形式. 一个被广泛使用的对偏置项的改进就是加入类别特定(class-specific)的偏置项, 即 $b_i = \tau_b log(n_i)$ , 而改进后的CE损失函数如下所示:
上式中的$\tau_b$使超参数, 用于控制偏置值的计算. $n_i$则为第i类的样本数量. 对于上述的引入样本数量的偏置值的设定, 由于模型训练过程中对损失函数的优化目标使使之最小化, 以CE为例的损失函数需要模型输出的logits和真实标签构成的one-hot向量, 而当构建上述偏置项后, 在损失函数的计算过程中相当于直接在logits上加入一个固定的向量, 使数量多的样本的logits天然偏大, 而真实标签是那些少量样本时, 在面对模型天然倾向误判为大样本的前提下会在训练中促使模型输出更大的原始logits的小样本项的值, 从损失函数反向传播的贡献上即小样本项会带来更大的梯度矩阵, 从而解决LT的问题.
然而, 从类间差距的角度出发(在cosine classifier的背景下, 这个差距就是不同类别在球空间中被分配的角度范围间的角度边界距离), 当 $n_y$ 明显大于 $n_i$时, CE损失有被缩小的倾向, 加入的偏置项有negative的作用. 为了解决这个问题, 作者提出了一个类别感知的间隔, 为头部的样本数量大的类别分配了更大的margin value作为补偿. 对应的margin value的数学表达形式如下:
上式中的$\tau_m$为用于控制m变化的超参数, s代表temperature, 用于拓展cosine形式下的输出值域. 结合margin value的CE损失函数的数学表达形式如下所示:
以笔者个人的理解来看, 本文作者在这里的改进的核心就是高级版的复杂版的水多加面, 面多加水, 由于softmax和交叉熵损失的计算固定, 仅就对模型输出的干净logits值的改动来看作者的改进. 原始的偏置项的作用可用下式表示:
其中的向量$\mathbf{b}$的分布特征是类别的数量越多, 对应位置分配的值越大, 却恒为正数. 在cosine classifier的背景下Logits的计算过程如下:
而作者的改进相当于对原始的Logits先减去一项, 再在后面加上一项, 反复进行拉扯来平衡最终的Logits的效果, 且当$i \neq y$ 时不执行减去的操作. 最终从Logits的视角模型的输出的数学形式如下所示:
只能说作者从一个刁钻的角度(AT训练)证实了加入采样偏置项带来的trade-off, 但提出的解决方案很难说有多么高明. 最后, 受AT训练框架的启发, 作者提出了在最终的训练损失中加入KL散度, 来制约对抗样本和干净图像之间的分布差距(可以理解为一种高级的范数约束, 散度是用来衡量两个概率分布间的相似情况). 最终的损失函数的数学表达形式如下:
对抗样本的产生则是基于vanilla CE loss. 此外, 对于two-stage的定义, 则是作者在推理阶段也对模型所用的偏置项进行了改进, 具体为减去一个采样偏置项来放大对小样本量类别的注意, 对应的数学表达形式如下:
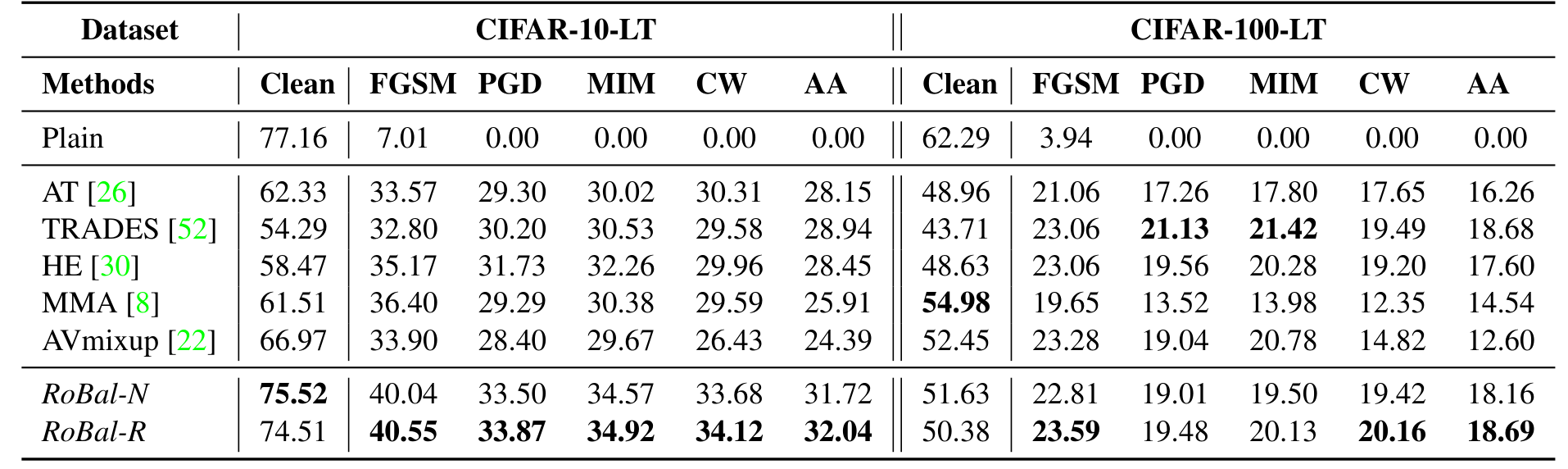
实验结果
作者进行了详尽的消融实验和结果分析. 这里仅展示相对重要的实验结果. 下图的N与R分别代表natural和robust, 对比结果如下:
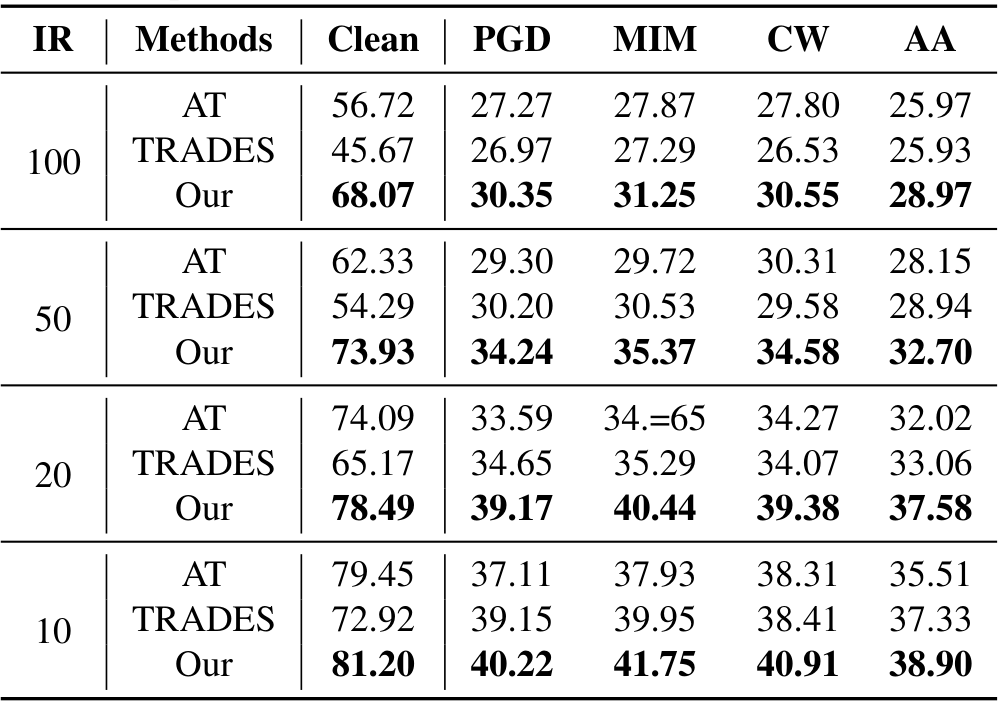
对于不同的数据长尾分布情况(即imbalance ratio, IR不同), 作者也进行了消融实验, 结果如下:
总结
本文最核心的创新视角在于用对抗样本和对抗攻击漂亮地解释了长尾分布方法中偏置项设置可能带来的trade-off, 说明对抗样本作为解释工具的巨大应用前景.