针对PolSAR和SAR的小样本Few-Shot场景改进CLIP模型框架
发表去向
论文发表于2025 TCSVT
创新点总结
在真实的SAR-ATR场景中, 对于非合作目标, 往往无法获得大量数据用于模型的训练, 因此需要关注Few-shot条件下SAR-ATR模型的性能. 随着CLIP等pre-trained模型在可见光图像zero-shot和few-shot任务上取得了优异的性能, 如何将其与SAR图像结合以解决跨域任务下(可见光->SAR)的少样本识别准确率, 作者结合预训练的CLIP模型提出了VLF-SAR(Vision Language Framework SAR)的少样本识别框架, 论文的主要创新点如下:
设计了频域嵌入模块(frequency embedded module, FEM)来提取图像中的频率域信息. 论文将所要识别的SAR图像分为了PolSAR和Traditional SAR两类, 并提出了相应的VLF-SAR-P和VLF-SAR-T.
对于VLF-SAR-P, 论文提出了名为polarimetric feature selector(PFS)的模块, 在图像结构相似度的基础上用于提取最合适的测定偏振向量, 为了实现不同偏振方向的向量之间的动态选取, 作者进而提出了adaptive multimodal triple attention mechanism(AMTAM). 此外, 作者引入了对比学习的方法, 通过将上述feature 划分为positive和negative来增强对于feature的区分和选取.
对于VLF-SAR-T, 由于一般的SAR图像只包含反映了幅值信息, 作者针对此提出了multimodal fusion attention mechanism(MFAM)处理信息量相对较少的SAR图像.
核心方法
VLF-SAR的整体架构如下图所示:
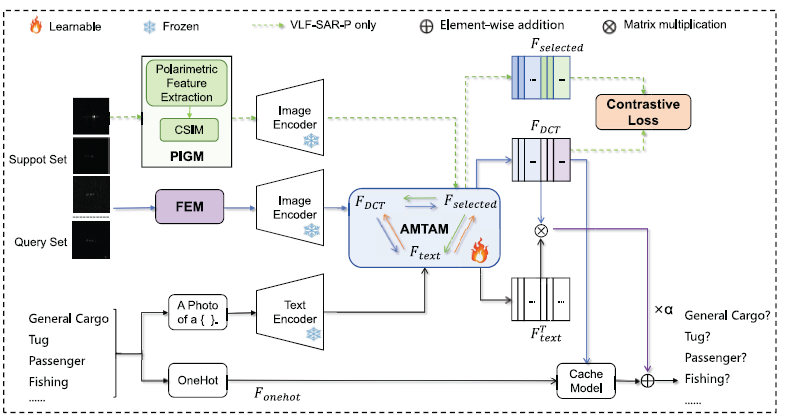
由于基于电磁散射的特殊成像机理, SAR图像呈现出包含大量散斑噪声, 高对比度和缺少自然色彩信息等特点, 也导致SAR图像和可见光图像之间存在巨大的domain gap. 在SAR成像过程中, 电磁波后向散射的信息会包含在成像结果的频率域当中, 因此作者提出了physical information guidance module(PIGM)来提取和利于图像频率域中所包含的物理信息.
FEM模块
该模块选择DCT进行空域SAR图像的频域转换, DCT变化的数学表达形式如下:
上式中的$\mathbf{I}(x,y)$为M*N的输入图像, $\alpha(\cdot)$为不同方向上的尺度缩放因子. 在进行DCT变换之后, 作者设定了全局阈值T来对频域矩阵进行阈值分割处理, T的表达形式如下:
上式中的n被设定为3, 来区分SAR图像的前景和背景. 根据T作者将DCT矩阵分为两份, 保留大于T部分的矩阵称为$D_{denoised}$, 另一个矩阵称为$D_{noise}$, 其中前者压缩了原始图像中的低频信息(denoise的对象则为高频的speckle noise), 后者则保留了高频信息. 此外, 作者提出了一种将单通道灰度PolSAR图像通过IDCT重建为3通道空域图像的方法, 其中各个通道的组成成分如下:
该重建操作主要目的是对齐CLIP模块三通道输入的要求, 同时对于PolSAR和SAR图像都可以提取到基础的图像信息.
VLF-SAR-P模块
在PolSAR图像的解译过程中, 极化特征向量包含着成像目标区域的物理特性信息. 因此, 在进行PolSAR图像的小样本分类时需要重点关注极化特征向量的提取与选择(因为polar feature 通常多余3个). 论文提出了极化特征向量选取算法, 基于SSIM(structural similarity index measure)进行改进, 提出了名为Combined Similarity Index Measure的特征向量评估方法. 对于SSIM, 数学表达形式如下:
上式中$\mu$为图像的均值, $\sigma$为图像的方差, 参数$C_1$和$C_2$被用于平衡分子和分母. 对于PolSAR图像, 背景散斑噪声占据了图像的主体部分, 会严重影响图像的均值与方差, 使不同图像间的差异被缩小或忽略. 因此作者提出使用Ostu图像分割算法提取PolSAR图像的主体部分并产生对应的mask掩膜矩阵, 再统计不同图像主体部分间的结构相似度, 这里所用于比较的图像为原始的PolSAR图像和所提取出的polar features. 掩膜矩阵M的定义如下:
上式中的$\sigma_B^2(\tau)$为类间差额阈值(between class variance threshold), $M(x,y)$为对应的掩码矩阵.由此可以获得如下表达式:
在此基础上, 作者引入了另一种度量矩阵FSIM, 会根据图像的梯度信息和相位一致性计算相似度, 对应的表达形式如下:
其中的$PC_x$为相位一致性, 其内涵为人眼观察下图像中的感知特征, 更能反映图像中例如边缘, 角点等显著的局部结构(体现在傅里叶频谱中的相位对齐); $GM_x$为像素点x的梯度值, 用于衡量局部区域的亮度变化率. 对于前者的计算基于局部能量模型, 使用一组具有不同尺度和方向的Log-Gabor小波滤波器对图像进行滤波. Log-Gabor是Gabor滤波器的变种, 在频域的传递函数(Transfor Function)服从对数高斯函数的分布. Log-Gabor的优势是可以在保持零交流分量的前提下构造具有任意带宽的滤波器, 滤波器对应的频率传递函数是两个函数的乘积:
其中$r = |f|$是径向频率(频谱中距离原点的距离), $\theta$是方向角度. $G_r(r)$的计算公式如下:
上式中的r是径向频率, $\sigma$是带宽参数, 在图像经过FFT后, 频谱图中的每个点(u,v)都代表一个二维坐标频率, r则是从原点到(u, v)的欧氏距离, 即 $r = \sqrt{u^2 + v^2}$ , 反映了图像中空间变化的快慢. 径向频率越高, 图像对应区域的纹理或边缘变化越密集精细. 而方向相应, 其决定了滤波器对哪个方向的结构最敏感, 数学表达形式如下:
上式中$\theta$为当前频率点的角度, $\theta_0$为中心方向, 决定了滤波器相应最大的方向, $\sigma_{\theta}$为方向带宽参数, 控制方向相应的宽度. 原始的Gabor滤波器则是高斯包络与复正弦平面波的乘积, 数学表达形式如下:
其中的$\lambda$为正弦波波长(与中心频率成反比), $\theta$为滤波器方向, $\psi$为相位偏移, $\sigma$为高斯包络的标准差, $\gamma$为空间纵横比(控制包络的椭圆度), $x’, y’$为旋转后坐标, 用于实现$\theta$.
回到FSIM的计算定义, 对于相位一致性$PC_x$, 其计算会使用一组具有不同尺度和方向(M个尺度, N个方向)的Log-Gabor小波滤波器对图像进行滤波, 对于每个尺度m和方向n, 滤波结果都包含实部$E_{m,n}^R(x)$和虚部$E_{m,n}^I(x)$, 通过根据这个复数结果即可获取幅值信息和相位信息, 局部幅值与相位的数学形式如下:
则PC的计算公式为:
上式中的$\Delta \Phi_{m,n}(x)$ 用于衡量不同尺度上的相位偏离其加权平均相位的程度, $\sum_n \sum_m A_{m,n}(x) \cdot \Delta \Phi_{m,n}(x)$为局部能量, 表示所有尺度和方向上的小波幅值和, $\epsilon$为取值较小的常数, 用于放置除零. $\Delta \Phi_{m,n}(x)$的数学表达形式如下:
其中$\bar{\Phi}(x)$为加权平均相位. PC值越高, 表示该像素所有尺度和方位上的小波相位越一致, 结构越显著. 对于梯度幅值的计算则较为简单, 在空域中使用标准的梯度算子(如Sobel算子或Prewitt算子)即可完成, 梯度幅值为水平梯度矩阵和垂直梯度矩阵的几何平均数.
FSIM算法在计算出参考图像X和给定图像Y的PC和GM图后, 会进而计算他们在每个像素上的相似度, PC相似度和GM相似度的计算公式如下图所示:
对两个相似度进行融合即可得到局部相似度, 用$\alpha$和$\beta$进行加权, 通常直接求和, 表达形式如下:
最终的FSIM分数为对局部相似度图进行加权平均得来, 权重使用两幅图像中的PC值的最大值:
在论文设定中, FSIM不需要使用由Ostu所提取的mask矩阵, 最终的混合相似度CSIM表达式为:
作者通过该结果同时考量了极化特征向量与原图的结构相似度和感知相似度. 最终作者挑选CSIM最大的极化特征作为结果.
此外, 为了向CLIP模型中引入领域知识(如PolSAR图像中的物理信息), 作者提出了自适应多模态三重注意力机制(Adaptive Multimodal Triple Attention Mechanism, AMTAM), 对应框架图如下所示:
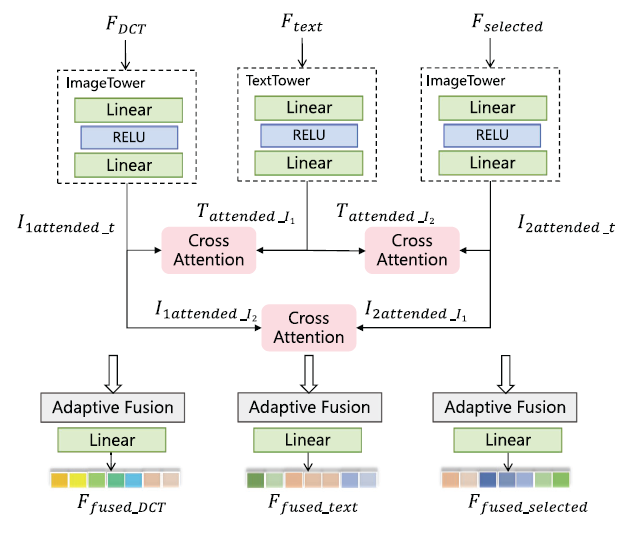
对于图像特征I和文本特征T, CLIP模型进行的注意力机制操作主要如下:
作者上文中通过PFS模块引入了多个额外极化特征矩阵作为SAR图像特殊的物理信息, 因此将其多为额外的模态, 引导模型动态的平衡不同模态间的输入对最终决策的贡献, 最终的合成文本向量代表了原始的文本向量和额外的被注意图像向量的加权和, 权重w为可训练参数, 使用softmax确保其归一性, 表达形式如下:
其中$T’’$的计算表达形式如下, 上文中注意力计算所用T矩阵为该输出结果:
上式中的T为文本的embedding feature, $\sigma$代表ReLU等激活函数. 以文本表征(text representation)为例, 最终的融合结果如下:
综上, 对于AMTAM模块, 其主要功能是对不同模态的特征进行了动态和自适应的融合.
对比学习
研究表明, 对比学习(contrastive learning)在少样本学习的分类任务中具有显著的有效性. 基于此, 作者提出了针对SAR图像少样本识别的改进对比学习模块. 基于上述的$AMTAM-I_{DCT-3}$ 和相应的极化特征结果, 结合对应的相同样本作为positive pairs, 其余的$I_{DCT-3}$的samples作为negative samples, 对应的对比学习损失函数如下:
上式中的$f_i^D$和$f_i^P$分别代表$I_{DCT-3}$特征和对应的极化特征, $d(\cdot, \cdot)$是欧氏距离. margin项确保模型可以在不破坏特征空间的情况下高效区分出不同的样本. 结合分类器原有的交叉熵损失, 最终VLF-SAR-P的损失函数的数学形式如下:
VLF-SAR-T
与PolSAR图像不同, 一般的SAR图像仅包括强度信息(即幅值信息), 因此需要对已有架构进行进化, 对应的VLF-SAR-T的模型架构仅包括FEM和MFAM, 前者已在上文中说明. 对于MFAM, 其目的在于优化文本信息和SAR图像信息的融合(而不设计极化特征向量), 相应的模型结构如下图所示:
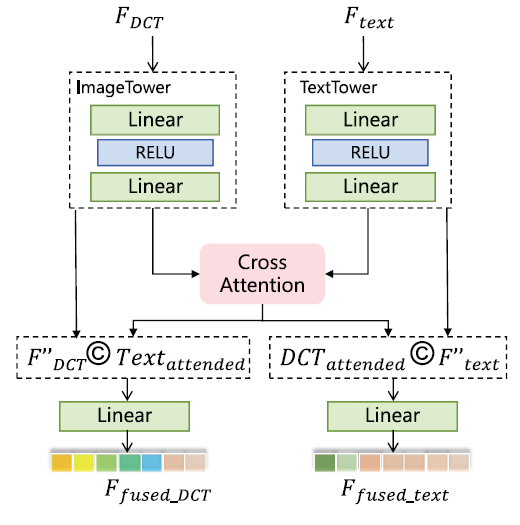
上图中起始的输入特征由冻结的CLIP模型的encoders提取获得, 经过简单的MLP和交叉注意力模块处理后获得互相关特征, 接着与原有的图像特征和文本特征进行拼接融合, 选择的方法是简单的拼接操作(concatenation), 对应的数学表达如下所示:
上式中的$\copyright$表示concatenation操作, $L(\cdot)$代表线性变换.
实验结果
作者选用了多个数据集, 包括包含PolSAR图像的opensarship2.0数据集和普通SAR图像的FuSAR-ship数据集, 并进行了包括消融实验在内的多项完备实验对比, 此处仅展示核心实验结果. 对于PolSAR和SAR图像, 模型fewshot的结果如下图所示:
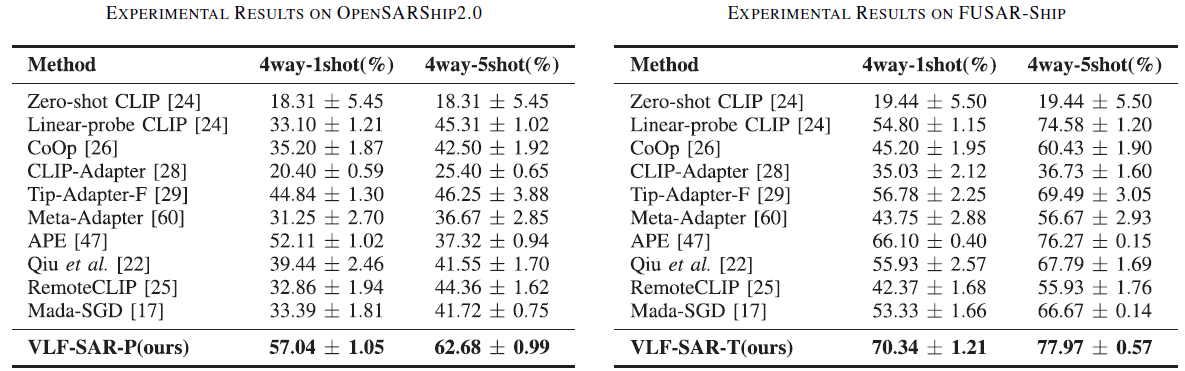
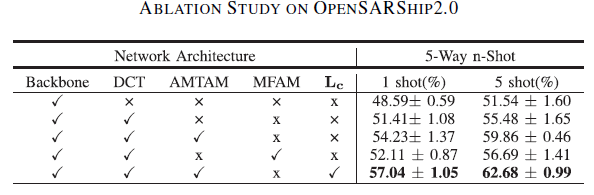
由于作者在文中引入了多个改进模块, 关于不同模块有效性的消融实验结果如下:
总结
本文作者提出了针对PolSAR和SAR图像的few-shot场景下的优化框架VLF-SAR, 并以CLIP模型为主体, 通过加入多个优化模块实现更好的少样本分类性能. 然而当前模型仍存在以下不足: FEM模块进行极化特征提取时依赖先验的阈值设定; 没有展开对于未知类别分类性能的测试.
代码复现
对于论文中的FEM模块, 即用DCT与IDCT进行特征矩阵提取, 笔者进行了简单的复现, 针对batch形式的tensor场景, 选用torch-dct库, 对应的复现代码和可视化结果如下所示:
复现代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66import cv2
import torch
import torch_dct as dct
import matplotlib.pyplot as plt
import numpy as np
polsar = cv2.imread("sarship.jpg")
polsar_rgb = cv2.cvtColor(polsar, cv2.COLOR_BGR2RGB)
polsar_torch = torch.from_numpy(polsar_rgb).permute(2,0,1).float()
polsar_batch = torch.unsqueeze(polsar_torch, dim = 0)
polsar_dct = dct.dct_2d(polsar_batch)
channels_mean = torch.abs(polsar_dct).mean(dim=(2,3)) # (batch_size, channels)
T = 3 * channels_mean[..., None, None]
D_denoise = polsar_dct * (torch.abs(polsar_dct) < T).float()
D_noise = polsar_dct * (torch.abs(polsar_dct) >= T).float()
I_denoise = dct.idct_2d(D_denoise)
I_noise = dct.idct_2d(D_noise)
I = polsar_batch
I_denoise_np = I_denoise.cpu().detach().numpy()[0] # 选择第一个batch的第一个通道
I_noise_np = I_noise.cpu().detach().numpy()[0] # 选择第一个batch的第一个通道
I_np = I.cpu().detach().numpy()[0]
def normalize_255(img_np):
if len(img_np.shape) == 2:
img_normalized = (img_np - img_np.min()) / (img_np.max() - img_np.min() + 1e-8)
return (img_normalized * 255).astype(np.uint8)
elif len(img_np.shape) == 3 and img_np.shape[2] == 3:
channel_mins = img_np.min(axis = (0,1), keepdims = True)
channel_maxs = img_np.max(axis = (0,1), keepdims = True)
channel_ranges = channel_maxs - channel_mins
channel_ranges[channel_ranges == 0] = 1
img_normalized = (img_np - channel_mins) / channel_ranges
return (img_normalized * 255).astype(np.uint8)
I_denoise_vis = normalize_255(np.transpose(I_denoise_np, (1,2,0)))
I_noise_vis = normalize_255(np.transpose(I_noise_np, (1,2,0)))
I_vis = normalize_255(np.transpose(I_np, (1,2,0)))
plt.figure()
plt.subplot(1,3,1)
plt.imshow(I_vis)
plt.title("original image")
plt.axis('off')
plt.subplot(1,3,2)
plt.imshow(I_denoise_vis )
plt.title("denoise feature")
plt.axis('off')
plt.subplot(1,3,3)
plt.imshow(I_noise_vis)
plt.title("noise feature")
plt.axis('off')
plt.tight_layout()
plt.show()
PolSAR图像的可视化结果(采用OpenSARShip2.0数据集)如下:

SAR图像的可视化结果如下:
