关于PGD攻击LoRa形式初始化改进算法的笔记
发表去向
arxiv版本, 暂未发表
预备知识
PGD优化与PGD Attack
投影梯度下降(Projection Gradient Descent)原本是一种鲁棒优化算法, 其核心思想是设定一个梯度下降的范围边界, 当每次下降的结果超出边界后就将其投影到边界上距离最近的位置, 其应用目标是解决带约束的优化问题. PGD的对应数学形式如下所示:
上式中的$\alpha_t$是更新步长, $\Pi_C(\cdot)$是到集合C的欧氏距离投影函数, 如果C是简单的集合(如盒子, 球或非负正交等), 则投影有显示表达式, 投影函数的数学表达如下:
以$L_2$球约束为例, 相应的函数形式为:
在PGD Attack算法中, 将目标函数设定为模型的损失函数, 采用的投影算子除上述$L_2$外还有$L_\infty$, 对应的数学表达形式如下:
对于untargeted attack的设定, 相应的PGD优化形式如下:
在PGD Attack算法中, 对于初始矩阵的选取较为敏感. 如果直接选取图像$x$, 训练时的计算开销较少但更容易陷入局部最优, 弱化最终的攻击效果. 常用随机均匀初始化(在x附近加入随机均匀扰动)或采用球面采样; 此外也有用单步FGSM作为目标引导的初始化方法.
SVD与LoRA分解
SVD
关于矩阵奇异值(Singular Value)的定义如下: 设A是 $m \times n$的实矩阵, 如果存在非负实数$\sigma$以及n维非零实数向量$\alpha$, m维非零实数向量$\beta$, 使
则称$\sigma$是A的奇异值, $\alpha$和$\beta$分别称为A关于$\sigma$的左奇异和右奇异向量.
相应的奇异值分解(SVD)的定义如下, 对应矩阵A存在以下分解:
上式中的$U \in R^{m \times m}$为正交矩阵, $V \in R^{n \times n}$为正交矩阵, $\Sigma \in R^{m \times n}$为对角矩阵, 对角线上的非负实数均为奇异值. 若A的秩为r, 则只有前r个奇异值严格大于0. Eckart-Young则说明了SVD分解下的低秩最佳近似, 对任意的$k < r$, 令$M_k = U_k \Sigma_k V^T_k$(取前k个奇异值), Echart-Young定理说明:
$M_k$是所有秩不超过k的矩阵中还Frobenius范数意义下与M最接近的:
相应误差则是奇异值的尾部
因此截断SVD是做低秩近似的最优解.
奇异谱
奇异谱刻画了矩阵的能量分布和结构复杂度. 对于矩阵A而言, 对应的奇异谱Frobenius Norm为:
奇异值越大, 表明矩阵的能量集中在对应方向. 此外, 奇异值谱的核范数形式如下:
上式为奇异值谱的L1范数, 核范数强调低秩, 会惩罚较大的奇异值; 是秩函数的凸松弛; 作为一种结构约束常用于低秩恢复, 矩阵补全等.
LoRA
由于大模型的训练权重往往较大, LoRA(Low-Rank Adaptation)的动机是冻结预训练参数$W_0$, 仅仅学习一个低秩增量$\Delta W$, 使最终的权重为$W_0 + \Delta W$, 同时强制$\Delta W$为秩为r的矩阵, 其对应表达形式如下:
其中$A \in R^{r \times d_{in}}$, $B \in R^{d_{out} \times r}$. 对于A和B的初始化, 常见的作法为使B初始化为全0矩阵, A随机为一个较小的矩阵.
创新点总结
作者提出PGD方法会主要攻击目标图像奇异值谱(singular value spectrum)中的低频部分(lower part), 因此作者提出了PGD攻击的变化形式, 重点对输入图像的low rank部分进行攻击优化的计算, 结果表明该方法可以等同甚至在部分场景下优于full-rank PGD Attack, 同时显著降低了对显存的占用.
算法细节
对于一般的分类器对抗攻击场景, 优化目标的数学表达形式如下:
上式中的C指代$\mathbb{R}^{C \times N \times M}$的输入格式, Y为误分类目标向量, $f_\theta$为分类器与对应参数, $\mathbb{l}$为损失函数. 对于经典的PGD攻击算法, 其扰动迭代过程如下:
上式中的$\Pi(\cdot)$为投影函数. 对于low-rank攻击, 相应的攻击优化目标的数学表达形式如下:
鉴于秩约束本身包含复杂的几何特性, 因此一个简单的解决方案在扰动矩阵上叠加(superimpose)低秩表征, 对应的优化形式如下:
上式中的$\otimes_C$代表channel-wise的张量乘法. 相应的对扰动矩阵U和V的迭代公式如下:
在原始图像上的扰动部署形式如下:
上式中的clamp部分扮演了优化过程中的投影函数. 对于扰动幅度$\tau$, 其值的确定主要参考$l_p$ norm, 为了从秩的角度确定扰动的上限, 作者考虑了扰动奇异值的核范数结果, 设定$R = min(N, M)$, 对应的范数矩阵设定如下:
最终, LoRa-PGD Attack算法的伪代码流程如下表所示:

实验结果
首先, 作者提出了三种实验的初始化方式:
Random Initialization: 与原始LoRa方法的初始化方式相同, 从Gaussian distribution中进行随机采样作为初始化的扰动矩阵, 同时其他部分设为0, 该方式可以确保优化过程从原始图像X开始.
Transfer Initialization: 对于固定的数据集, 首先计算full-rank FGSM攻击的结果并将其作为PGD和LoRa-PGD攻击的输入样本.
Warm-up Initialization: 该方式与Transfer Initialization类似, 即对每一个特定的模型和数据集都进行专门的FGSM计算并将结果对抗样本作为攻击算法的优化起始点.
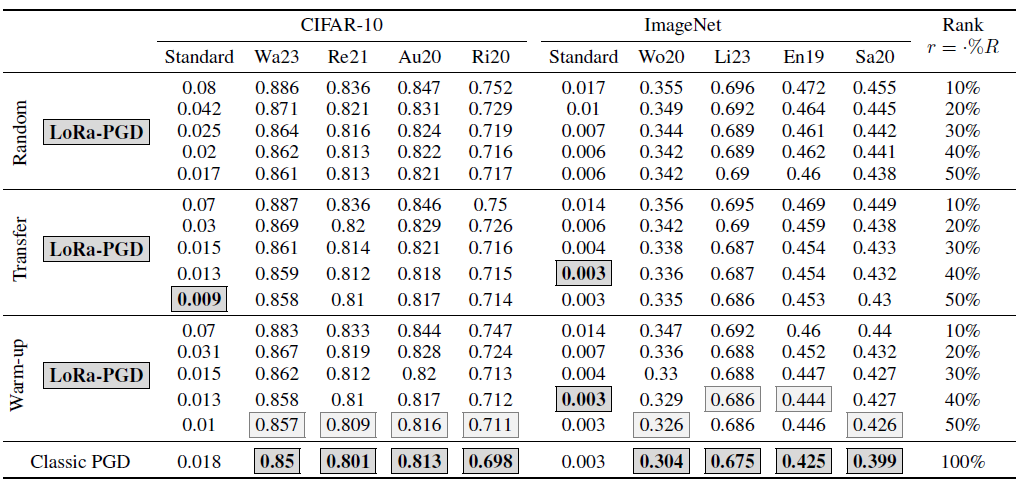
初步的实验结果如下:
此外, 笔者也对该算法进行了简单的复现(主要参考原作者的开源代码), 在MSTAR数据集上对VGG模型进行白盒攻击测试, 基于原始代码的参数设定和攻击结果如下:
- 参数设置: 迭代轮次300, eps=50/255, eps_division=1e-10, rank=0.2
- 攻击结果: Benign样本分类ACC为0.9641, 对抗样本分类ACC为0.6103
生成的对抗样本如下图所示:

原始的攻击效果与PGD算法相比(eps=32/255, alpha=32/255,steps=300, ACC结果0.2154), 改进的声称SOTA的算法并没有显示出优越的攻击效果, 后续实验中即使将参数设置为较为极端的情况也难以实现理想的攻击. 通过对PGD和LoRa-PGD产生的对抗样本进行比较发现, 现有算法很难产生较大幅度的扰动, 而对MSTAR数据集而言难以获得类似光学图像上的理想效果. 限制算法在极端参数下仍无法有效产生大幅度的扰动矩阵的原因主要是对于低秩矩阵进行了全0初始化, 同时对扰动矩阵进行了较强的归一化. 针对上述两点, 分别对两个低秩矩阵进行随机初始化, 同时省略最终扰动矩阵的归一化过程. 进行上述改进后与PGD算法对比的对抗样本图像如下所示, 最终的对抗样本ACC为0.1949:

实验的复现代码如下, 以供读者参考:
1 | class LoRa_PGDAttack: |
总结
作者针对PGD Attack, 从矩阵值的角度进行了优化, 但核心的观察仍然是出自图像的频率域. 通过频率变化相信可以获得自然图像中人眼和人脑(包括模型)感知学习到而不自知难察觉的信息. 但是遗憾的是, 原文并没有使用频率分析工具(FFT, DCT等)对改进前后的结果进行定量或者可视化的比较, SVD在代码实现中的体现也不够充分, 重点是参考了LoRa的初始化思路.