dataset similarity measure调研与简单复现
Feuer et al.[1]提出使用meta-learning来有效初始化Sequential Model-Based Bayesian Optimization(SMBO)过程. 所设定的前提是在待度量的数据集集合中的每个数据集$D^{(i)}$都可以用K个metafeature描述, 即 $m^i = (m^i_1, m^i_2, … \ ,m_k^i)$. 作者进而提出两种距离度量方法, 一种是直接度量metafeature集的距离作为数据集之间的距离:
第二种度量方法通过negative Spearman correlation度量不同超参数设定的模型性能并将其作为metafeature集合, 对应表达形式如下:
上式中$g^{D^{(i)}}(\cdot)$代表含参目标函数. 当需要在多个数据集中匹配最相似的数据集时, 由于参数无法固定下来, 因此需要借助mapping function在metafeature对$(m^i, m^j)$和$D_{Fc}(D^{(i)}, D^{(j)})$之间进行回归. 常用的metafeature可以归为以下几个大类:
用于描述或者量化数据集的简单特征
PCA metafeatures
数据集的熵值
统计特征, 包括数据集的峰度(kurtosis)或者标签的分布宽度(dispersion of label distribution)
landmarking metafeatures(通过快速的ML算法获得, 如linear separability)
上述中的峰度kurtosis是指用于描述概率分布曲线在平均值处峰值高低以及尾部厚度的统计量, 用于衡量数据特征的离散程度和异常值的存在情况. 对应数学表达如下:
上式中X为特征变量, $\mu$是均值, $E$是期望算子, $\sigma$是标准差, $\mu_4$是4阶中心矩.
标签分布宽度则描述了类别分布的平衡程度或离散程度, 可以用类别概率标准差衡量, 对应数学表达形式如下:
上式中C是类别总数, $p_i$是第i类的样本比例.
此外, 式(2)中所用的Spearman相关系数为范围在[-1,1]间的统计值, 用于度量两组排序(ranks)结果的相关强度, 该系数可以用于衡量数据和模型的契合程度, 对于n对原始分数对$(X_i, Y_i)$, 将其转换为ranks$R[X_i], R[Y_i]$, 令$R[X_i], R[Y_i] = (R_i, S_i)$, 对应的相关系数计算如下:
上式中的rank不是矩阵的秩, 给定$\{X_1, X_2, …, X_n \}$, 对其进行排序后rank的定义为$R(X_i)$为在排序序列中$X_i$的位置. 当不存在并列的情况时, 表达式可简化为:
以SAMPLE数据集以及光学的CIFAR10为例, 通过以下代码可以初步计算real和synth子数据集和光学CIFAR10数据集的峰度和标签分布差异.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 import osimport torchimport torchvision.transforms as transformsfrom torch.utils.data import DataLoader, Datasetfrom PIL import Imageimport numpy as npclass ImageClassificationDataset (Dataset ): def __init__ (self, root_dir, transform=None ): self .root_dir = root_dir self .transform = transform self .classes = sorted (os.listdir(root_dir)) self .class_to_idx = {cls: idx for idx, cls in enumerate (self .classes)} self .samples = [] for class_name in self .classes: class_dir = os.path.join(root_dir, class_name) if not os.path.isdir(class_dir): continue for file_name in os.listdir(class_dir): file_path = os.path.join(class_dir, file_name) self .samples.append((file_path, self .class_to_idx[class_name])) def __len__ (self ): return len (self .samples) def __getitem__ (self, idx ): img_path, label = self .samples[idx] image = Image.open (img_path).convert('RGB' ) if self .transform: image = self .transform(image) return image, label def extract_features_from_images (dataset, batch_size=32 , num_workers=4 ): dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=False , num_workers=num_workers) all_pixels = [] all_labels = [] for images, labels in dataloader: pixels = images.view(images.size(0 ), -1 ) all_pixels.append(pixels) all_labels.append(labels) pixel_data = torch.cat(all_pixels, dim=0 ) label_data = torch.cat(all_labels, dim=0 ) return pixel_data, label_data def calculate_kurtosis (tensor ): """ tensor: shape [n_samples, n_features] """ mean = torch.mean(tensor, dim=0 ) std = torch.std(tensor, dim=0 ) standardized = (tensor - mean) / (std + 1e-8 ) fourth_moment = torch.mean(standardized ** 4 , dim=0 ) kurtosis = fourth_moment - 3 return kurtosis def analyze_label_distribution (labels ): unique_labels = torch.unique(labels) num_unique_labels = len (unique_labels) label_counts = torch.bincount(labels) distribution_std = torch.std(label_counts.float ()) probabilities = label_counts.float () / torch.sum (label_counts) entropy = -torch.sum (probabilities * torch.log(probabilities + 1e-8 )) return { 'num_unique_labels' : num_unique_labels, 'label_counts' : label_counts, 'distribution_std' : distribution_std, 'entropy' : entropy, 'probabilities' : probabilities } def analyze_dataset (dataset_path, img_size=224 , batch_size=256 ): transform = transforms.Compose([ transforms.Resize((img_size, img_size)), transforms.ToTensor(), ]) dataset = ImageClassificationDataset(dataset_path, transform=transform) pixel_data, label_data = extract_features_from_images(dataset, batch_size) sample_indices = torch.randperm(pixel_data.shape[1 ])[:10000 ] sampled_pixels = pixel_data[:, sample_indices] kurtosis_values = calculate_kurtosis(sampled_pixels) label_stats = analyze_label_distribution(label_data) return { 'kurtosis_mean' : torch.mean(kurtosis_values), 'kurtosis_std' : torch.std(kurtosis_values), 'label_distribution_std' : label_stats['distribution_std' ], 'label_entropy' : label_stats['entropy' ], 'num_classes' : len (dataset.classes), 'total_samples' : len (dataset) } if __name__ == "__main__" : synth_dataset_path = "./synth" real_dataset_path = "./real" cifar10_dataset_path = './cifar10' synth_stats = analyze_dataset(synth_dataset_path) real_stats = analyze_dataset(real_dataset_path) cifar10_stats = analyze_dataset(cifar10_dataset_path) print (f"{'result' :<20 } {'Synth' :<15 } {'Real' :<15 } {'CIFAR10' :<15 } " ) print ("-" * 50 ) print (f"{'kurtosis_mean' :<20 } {synth_stats['kurtosis_mean' ]:<15.4 f} {real_stats['kurtosis_mean' ]:<15.4 f} {cifar10_stats['kurtosis_mean' ]:<15.4 f} " ) print (f"{'label_std' :<20 } {synth_stats['label_distribution_std' ]:<15.4 f} {real_stats['label_distribution_std' ]:<15.4 f} {cifar10_stats['label_distribution_std' ]:<15.4 f} " ) print (f"{'label_entropy' :<20 } {synth_stats['label_entropy' ]:<15.4 f} {real_stats['label_entropy' ]:<15.4 f} {cifar10_stats['label_entropy' ]:<15.4 f} " )
特征结果如下所示1 2 3 4 5 result Synth Real CIFAR10 ------------------------------------------------------------- kurtosis_mean 1.1260 0.9982 -0.7343 label_std 30.2811 30.2811 0.0000 label_ entropy 2.2800 2.2800 2.3026
Gromov-Wasserstein距离 文献[2]提出基于Gromov-Wasserstein metric来度量数据集之间的相关程度, 对应数学表达如下所示:
上式实际度量了两个概率空间$\mathcal{X}$和$\mathcal{Y}$之间的距离, 其中的$\mathcal{X}$和$\mathcal{Y}$不仅包含距离结构$d_{\mathcal{X}}$, $d_{\mathcal{Y}}$, 还带有概率测度$\mu_{\mathcal{X}}$和$\mu_{\mathcal{Y}}$. $\pi$为最优传输理论中的联合概率测度, 对应的$\Pi(\mu_{\mathcal{X}}, \mu_{\mathcal{Y}})$是所有满足边缘约束的耦合集合. 当用于度量给定的数据集$\mathcal{X}=\{x_1, …, x_n \}$和$\mathcal{Y}=\{y_1, …, y_m\}$时, 对于度量空间$(\mathcal{X}, d_{\mathcal{X}})$的定义, $d_{\mathcal{X}}:\mathcal{X} \times \mathcal{X} \rightarrow \mathbb{R}_+$可以表示为如下形式:
其中的$\phi(\cdot)$为特征提取器. 对于概率测度$\mu_{\mathcal{X}}$和$\mu_{\mathcal{Y}}$, 在有限数据集上使用经验分布:
其中的$\delta$为狄拉克测度, 可以简单理解为每个$x_i$在数据集中的比例. 联合概率测度$\pi \in \Pi(\mu_{\mathcal{X}}, \mu_{\mathcal{Y}})$则表示一个软匹配关系, 对应表达形式如下:
GW距离并非衡量数据集中的点是否接近, 而是两个数据集的内部集合结构是否一致. 同上, 借助POT库(python optimal transport)可以实现GW的计算与可视化, 同样分别比较real-synth和real-cifar10, 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 import torchimport torchvision.transforms as transformsfrom torch.utils.data import DataLoader, Datasetfrom PIL import Imageimport numpy as npimport scipy as spimport otimport matplotlib.pyplot as pltfrom sklearn.decomposition import PCAfrom sklearn.manifold import TSNEfrom method1 import ImageClassificationDataset def extract_features_from_images (dataset, batch_size=32 , num_workers=4 ): dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=False , num_workers=num_workers) all_pixels = [] all_labels = [] for images, labels in dataloader: pixels = images.view(images.size(0 ), -1 ) all_pixels.append(pixels) all_labels.append(labels) pixel_data = torch.cat(all_pixels, dim=0 ) label_data = torch.cat(all_labels, dim=0 ) return pixel_data.numpy(), label_data.numpy() def load_dataset_features (dataset_path, img_size=32 , batch_size=256 ): transform = transforms.Compose([ transforms.Resize((img_size, img_size)), transforms.ToTensor(), ]) dataset = ImageClassificationDataset(dataset_path, transform=transform) features, labels = extract_features_from_images(dataset, batch_size) return features, labels def compute_and_visualize_gw_with_features (real_path, synth_path, feature_method='pixel' , img_size=128 ): real_features, real_labels = load_dataset_features(real_path, img_size) synth_features, synth_labels = load_dataset_features(synth_path, img_size) C1 = sp.spatial.distance.cdist(real_features, real_features) C2 = sp.spatial.distance.cdist(synth_features, synth_features) C1 /= C1.max () C2 /= C2.max () n_real, n_synth = len (real_features), len (synth_features) p = ot.unif(n_real) q = ot.unif(n_synth) gw, log = ot.gromov.gromov_wasserstein( C1, C2, p, q, "square_loss" , verbose=True , log=True ) plt.figure(figsize=(8 , 6 )) plt.imshow(gw, cmap='Blues' ) plt.title(f'GW Transport Matrix ({feature_method} )\nGW Distance: {log["gw_dist" ]:.6 f} ' ) plt.colorbar() plt.show() return { 'distance' : log["gw_dist" ], 'transport_plan' : gw, 'real_features' : real_features, 'synth_features' : synth_features } if __name__ == "__main__" : results = compute_and_visualize_gw_with_features("./real" , "./synth" ) results2 = compute_and_visualize_gw_with_features("./real" , "./cifar10" ) print ("\n" + "=" *50 ) print ("Gromov-Wasserstein Distance Results:" ) print ("=" *50 ) print (f"GW distance: {results['distance' ]:.6 f} " ) print (f"GW distance: {results2['distance' ]:.6 f} " )
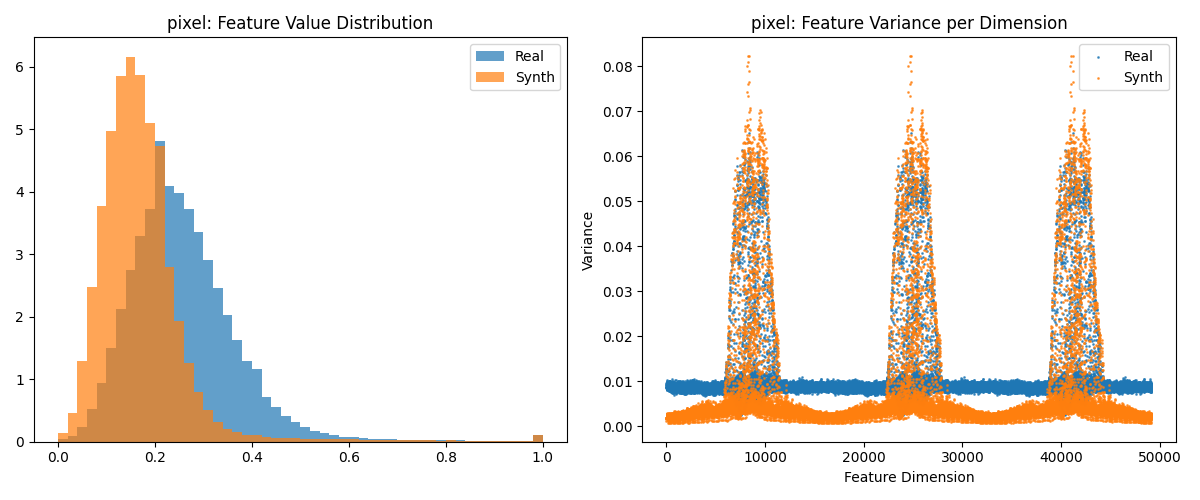
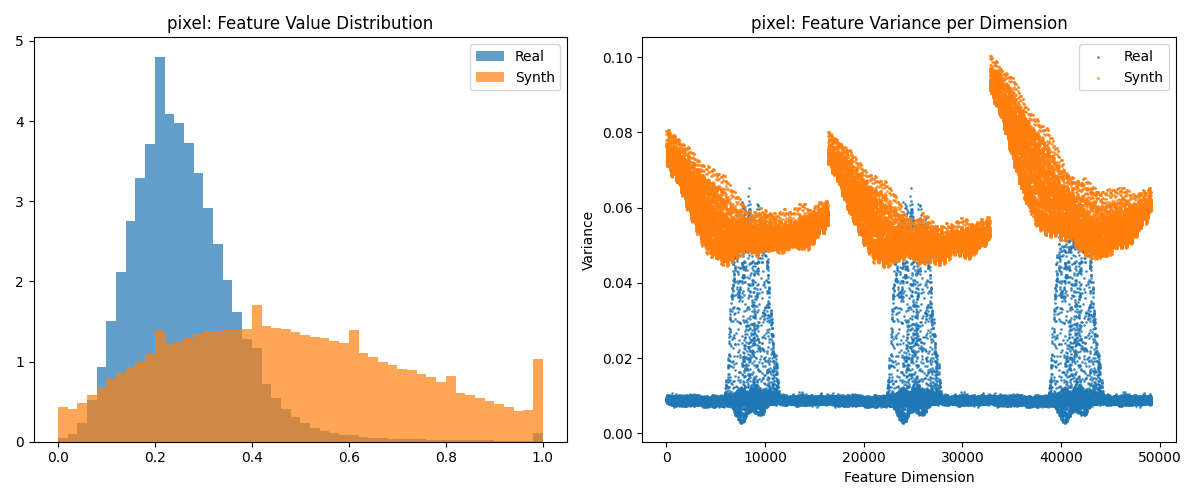
在分析实验结果之前, 首先对图像统计特征进行可视化. 将特征提取器设定为对图形简单一维展平, 获取特征集合的特征值分布图像和不同维度的方差分布, 结果从上至下分别为real-synth和real-cifar10, 下同. 对应可视化结果如下:
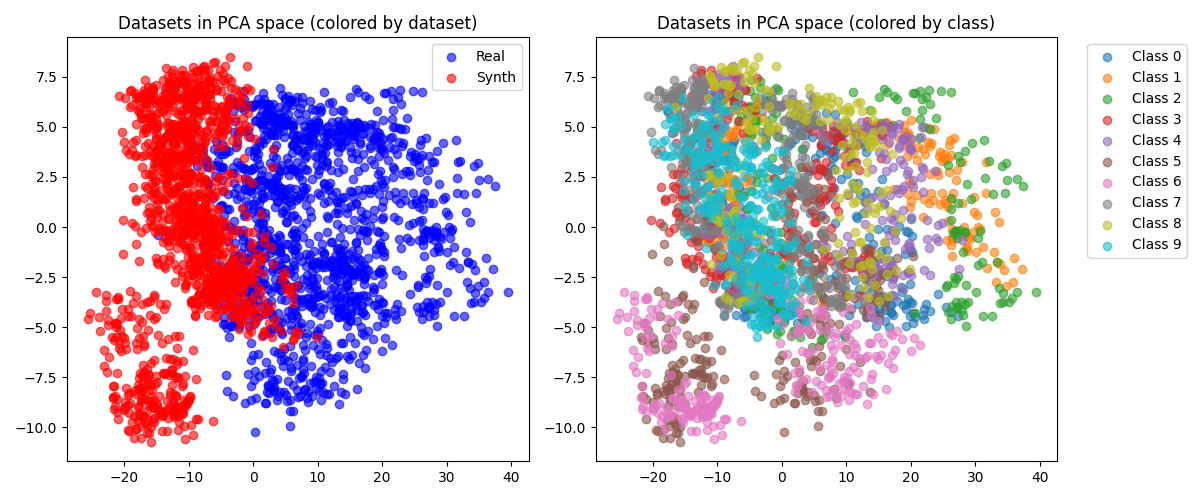
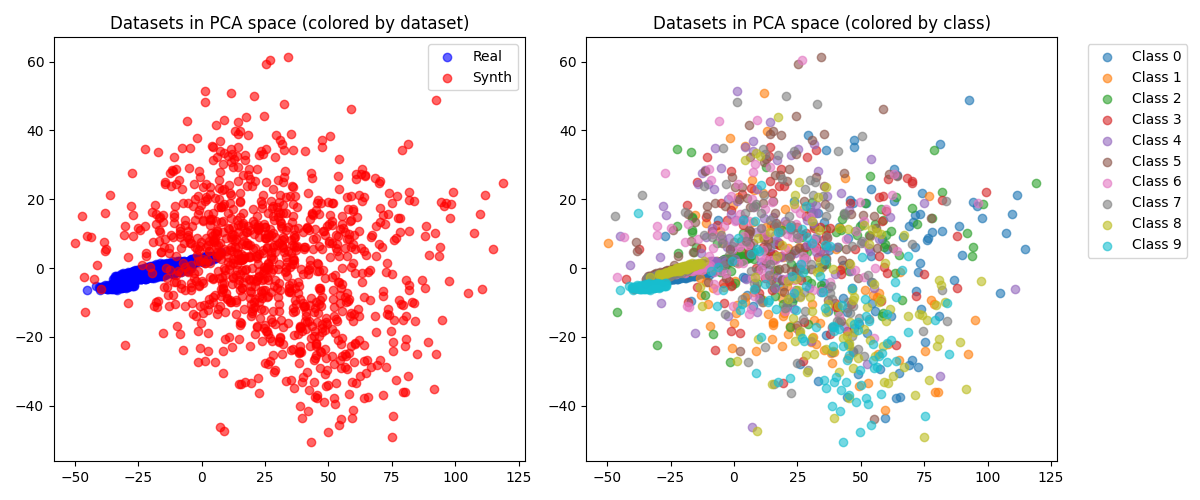
接着, 使用PCA对图像进行降维可视化, 分别按数据集和按类别进行着色区分, 可视化结果如下:
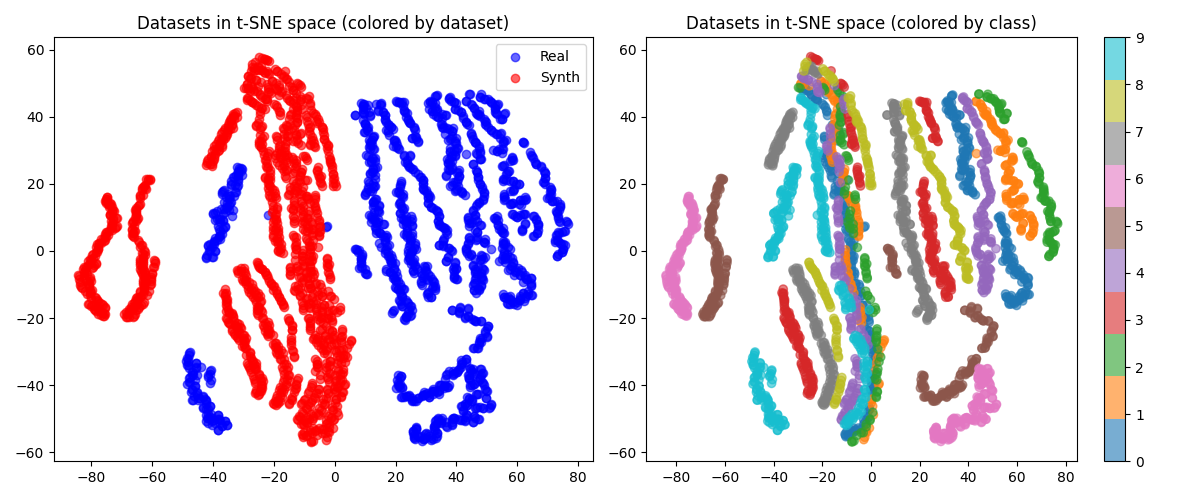
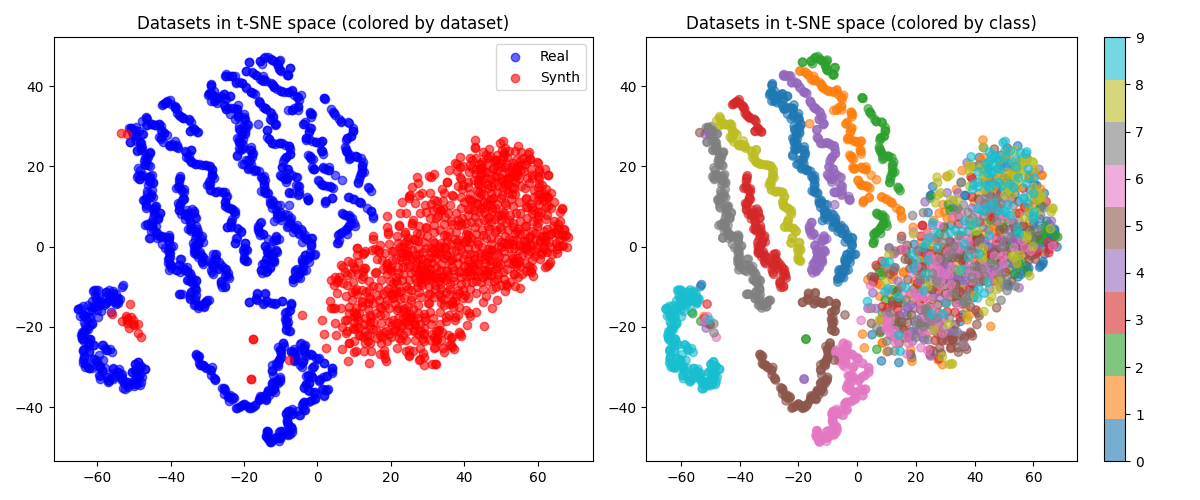
最终, 用t-SNE对展平的一维特征进行可视化处理, 对应结果如下所示:
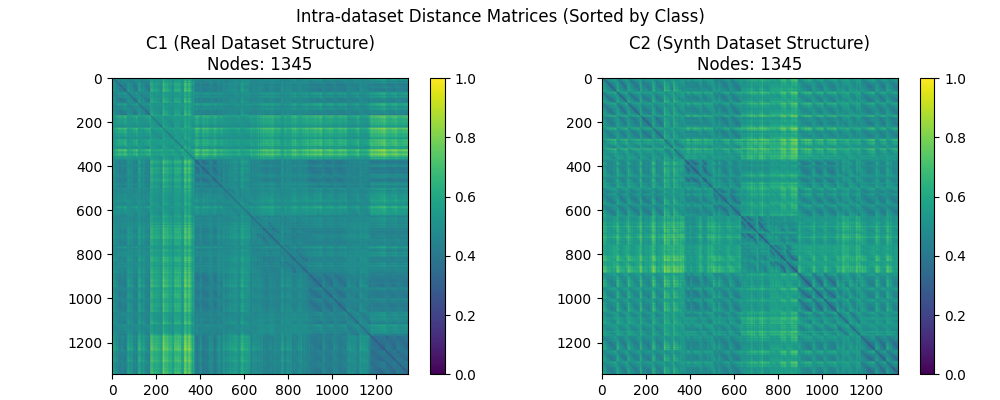
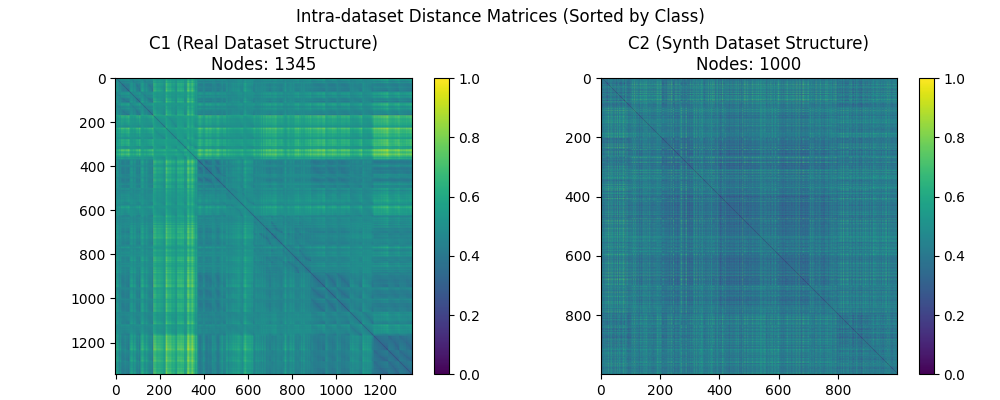
接着使用GW距离进行数据集相似度统计, 首先可以对代价矩阵(即由$d_{\mathcal{X}}$或$d_{\mathcal{Y}}$构成的元数据点两两之间距离匹配矩阵)进行可视化, 对应结果如下:
运行算法可得, 最终不同数据集对之间的GW距离结果如下:
1 2 3 4 5 ================================================== Gromov-Wasserstein Distance Results: ================================================== GW distance: 0.003756 GW distance: 0.011917
Deep Dataset Dissimliarity Measures(DeDiMs) 文献[3]提出了一种融合数据和标签分布以及半监督深度学习的数据分布匹配评估方法, 主要通过设计4个特殊的距离函数实现, 给定两个数据集$D^a$和$D^b$, 对应步骤如下:
对数据集进行随机采样, 在系数$\tau$的约束下获得两个对应的子集, 称为$D^{a,\tau}$和$D^{b,\tau}$
通过特征提取器(feature extractor)获得子数据集对应的特征向量集$H^{a,\tau}$和$H^{b,\tau}$
完成上述两个步骤后, 首先需要计算 Minkowski-based distance set, 对应的过程如下:
选取Manhattan距离或欧式距离(q-norm取1或2)计算距离$d_i=min_k |h_i - h_k |_q$, $h_i$为从$H^{a, \tau}$中采集C个样本构成, $h_k$是$H^{b, \tau}$中与之最接近的向量, 通过该步骤获取一个距离列表$d_{l_q}(D^a,D^b, \tau, C) = \{ \hat{d_1}, …,\hat{d_C}\}$
类似步骤1, 计算$D^a$的组内距离, 获得参考距离列表(reference distance list)$d_{l_q}(D^a,D^a, \tau, C) = \{ \check{d_1}, …,\check{d_C}\}$
计算上述两个距离列表的差值绝对值, 同时计算各个距离列表与自身均值的离散分布以及Wilcoxon test的p-value
上述方法可以视为基于比较密度方程(comparing density function)的数据集相似度评估算法, 计算过程同时评估的数据集内和不同数据集之间的距离差异, 可以更好地反映数据集之间的分布差异并提升半监督深度学习(semi-supervised deep learning ,SSDL)的性能.
此外, 上述的Minkowski distance, 也被称为Minkowski metric, 是一种正则化向量空间, 可以视为曼哈顿距离和欧式距离的推广. 对于两个向量集合$X = (x_1, x_2, …, x_n)$和$Y = (y_1, y_2, …, y_n)$, 对应计算公式如下:
该距离的设计启发来自Minkowski不等式, 通常p被设定为1或2, 分别对应曼哈顿距离和欧式距离. 闵氏距离可以理解为两个向量集合之间的能量平均. 对于Wilcoxson test, 有两种常见的检验定义, 分别为Wilcoxon Signed-Rank Test(符号秩检验)和Wilcoxon Rank-Sum Test(秩和检验), 前者基于成对样本, 后者则适用于独立样本, 没有一一对应关系. 此处采用的是Wilcoxon符号检验.
Wilcoxon符号秩检验是一种非参数假设检验方法, 用于比较两个配对样本是否有显著差异. 这里的秩是指数据绝对值大小所带来的排名. 对于两组距离列表, 首先计算每对数据的差值$D_i = x_i - y_i$, 当$D_i = 0$时会将该数据从分析中提出并对样本总数-1; 接着计算绝对值的秩, 对所有非零差值绝对值进行排序并从小至大赋予秩次$R_i$.
此外需要定义相应的符号函数$sgn(\cdot)$以规定差值的方向, 对应表达形式如下:
最终将符号秩总和作为检验结果:
对于上述假设检验或其他任意假设检验, 还可以用p值刻画分布的内涵. 其统一的定义为:
其中X为随机样本, $x_{obs}$为观测样本, $T(\cdot)$为检验统计量, $\mathbb{P}_{H_0}$为在原假设$H_0$成立条件下的概率. 对于Wilcoxon检验, 原假设为差值的中值为0, 即数据分布呈现中心对称.
参考文献 [1]: Initializing Bayesian Hyperparameter Optimization via Meta-Learning, AAAI
[2]: Modern approaches to discrete curvature, Book
[3]: Dataset Similarity to Assess Semisupervised Learning Under Distribution Mismatch Between the Labeled and Unlabeled Datasets, IEEE TRANSACTIONS ON ARTIFICIAL INTELLIGENCE