关于目标检测任务中的虚警(False Alarm)现象的相关论文的梳理
目标检测任务中的虚警问题
目标检测任务主流指标与对应数学表达
对于目标检测模型性能的度量,基础的指标为预测检测框与真实标签之间的交并比(Intersection over Union, IoU), 该指标度量了上述两种检测框之间重叠的程度, 令$B_{gt}$为真实框, $B_{p}$为预测框, 相应的数学表达式如下:
Precision则度量了所有正样本中真实正样本(true positive predictions)的占比, 其中TP的定义为当GT框还没被检测时, 第一个与GT框的IoU超过设定阈值的预测框则为TP, 其余的诸如未超过设定IoU阈值的或者对已经产生TP框的目标重复检测的预测框则归类为负样本FP, 对应表达形式如下:
对应的Recall则度量了所有真实正样本中被模型正确识别的比例, 用来模型检测图像中出现的所有相关目标的能力, 对应的表达形式如下:
为了调和Recall和Precision, 来更公平地评估检测模型的识别性能, 平均精度(Average Precision, AP)的概念被进一步提出, 代表了所有回归水平下的准确度的值(因此可以简单理解为P和R的积分). AP通过P-R曲线的面积获取, 对应曲线则通过设定不同的IoU阈值用于区分当前的TP, FP和FN, 通过一系列阈值的设定可以获取每个阈值下的Precision和Recall, 构成一个(R,P)点对坐标, 通过设定横轴为R, 纵轴为P则获取相应的PR Curve, 进而进行AP的计算. mAP则是针对多类别目标检测模型, 计算所有类别的AP值并取平均值. 对应的数学表达形式如下:
此外F1也是对Precision和Recall 的调和指标, 希望通过平衡二者来真实反映模型的检测性能, 对应数学表达形式如下:
红外小目标分割任务中的漏检和虚警
论文 Miss Detection vs. False Alarm: Adversarial Learning for Small Object Segmentation in Infrared Images 发表在2019ICCV, 在题目中明确提出了漏检(Miss Detection, MD)和虚警(False Alarm, FA)的问题, 虽然是针对语义分割任务, 但也给SAR图像的目标检测的虚警问题以定义和解决思路的启发.
作者提出针对红外小目标语义分割(infrared samll object segmentation, ISOS)任务, 一个关键的挑战即为MD和FA的平衡, 因为针对这两类问题的性能改善往往需要通过相反的策略并导致FA和MD难以在同一个改进策略下同时抑制. 在文章中作者则受cGAN网络的启发, 将MD和FA设定为了两个同等地位的子任务 ,设置了一种对抗训练策略来实现对MD和FA的平衡(Nash equilibrium). 具体的网络则是在cGAN的基础上引入了两个生成器和一个判别器, 并设置了不同的损失函数, 实验结果显示作者提出的网络超越的论文发表时的SOTA模型. 对应的改进模型架构如下图所示.
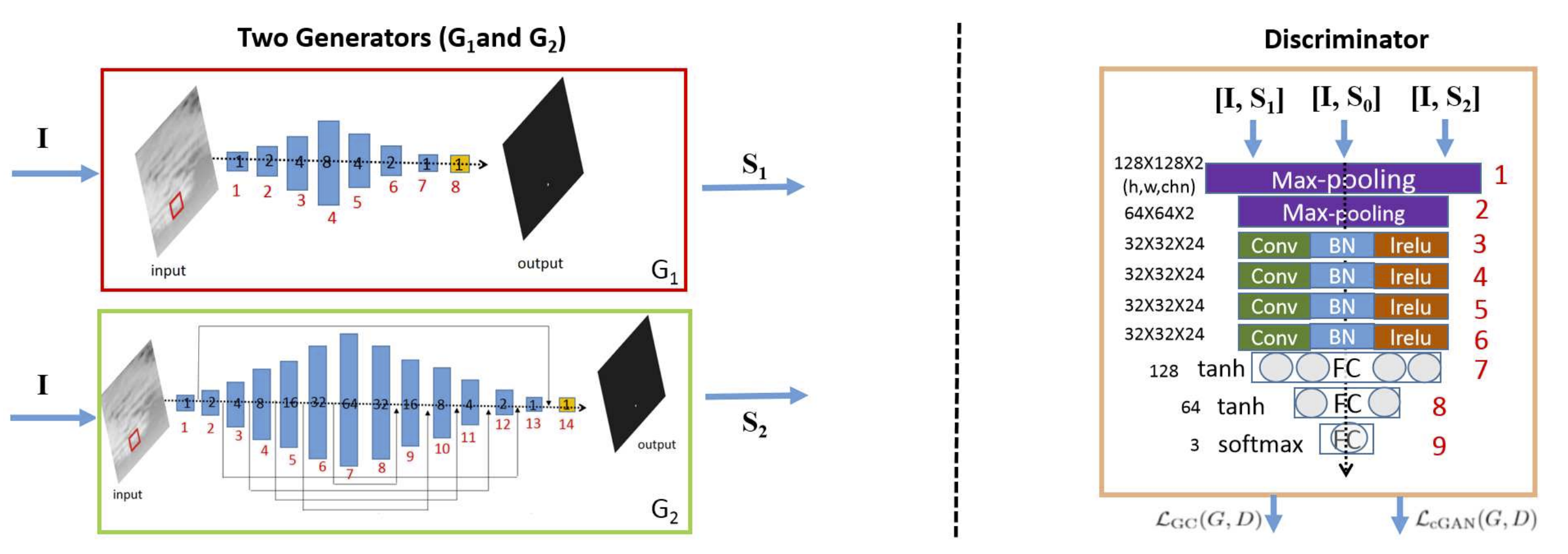
两个生成器对应两个子任务, 分别用于最小化MD损失或者FA损失. 相应的判别器D则改为三分类, 用于区分两个生成器和结果和对应的真实标签. 对于损失函数的设定, 作者设置了Adversarial Loss, Generator Consistency Loss和Data Loss三类. 对于第一项AL, 其综合了两个生成器的损失项, 优化目标为让两个子生成器的输出都尽可能逼近真实标签, 对应的数学表达形式如下:
对于第二项GCL, 其设计动机为使两个子生成器针对MD和FA的优化特征进行相应的平衡(即增强二者之间的information flow), 对应的数学表达形式如下:
上式中的$\phi(\cdot)$为对应的feature mapping函数, 用于提取G中的特征图, w,h和d则是相应卷积特征图的维度.
对于Data Loss, 其作用为对应cGAN的原始设置, 在忽略MD或FA度量的情况下反映像素层级的真实值与预测值之间的差异, 对不同的G设置的损失函数分别如下:
上式中的$MD_{1i}$和$FA_{1i}$是生成器$G_1$输出结果的对应漏检率和虚警率(但原文没有给出相应的数学表达). 另外一对同理. 最终的Data Loss表达式为:
结合GAN网络的对抗训练(min-max优化)特性, 最终的合并损失函数如下:
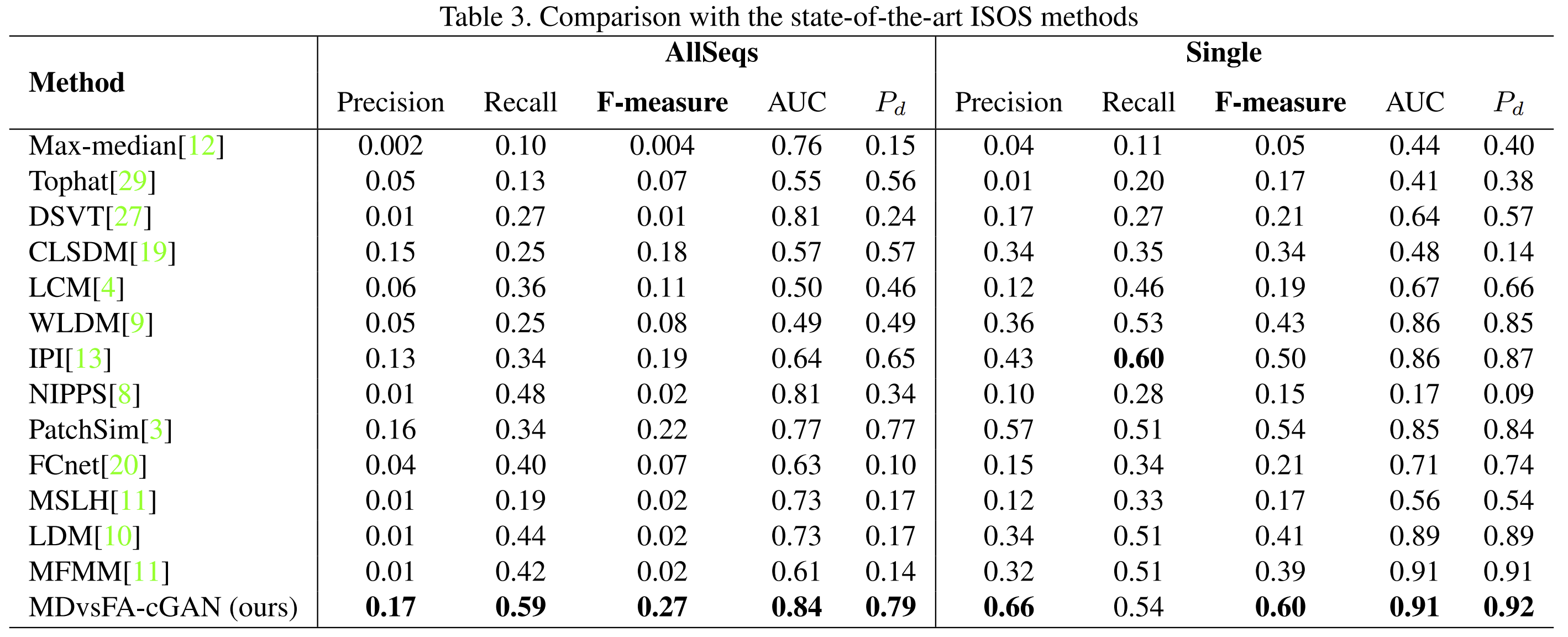
简要展示作者的实验结果, 对应如下:
视频变化检测任务中的虚警抑制
论文 Statistical Modeling of Deep Features to Reduce False Alarms in Video Change Detection 发表与2025年的JMIV, 提出了视频变化检测任务(Video Change Detection, VCD)中的一个核心问题: 虚警率(False Alarm Rate)过高, 并针对这一问题提出了针对性的解决方法, 但遗憾的是论文中的检测手段依然近似于语义分割.
传统的视频变化检测方法通常基于像素点的亮度或颜色信息,这种局部特性极易受到动态背景、光照变化或伪影的影响,从而产生大量虚警. 对此作者提出了一种弱监督的高维深度特征建模方法, 用特征数据替代原始像素实现更稳健的场景中背景模式的描述, 另外作者将背景特征建模为了高斯混合分布, 采用全局-局部的策略进行精细化的背景统计分布建模.
文中作者提出了A-contrario detection theory作为关键方法, 其核心为对于非偶然内容的数学表达(mathematical formulation of the non-accidentalness principle), 指出被观察的结构只有在非偶然的背景模型中出现才能被认为是有效的检测, Number of False Alarms(NFA)是事件e的观测结果, $z(e)$是对应概率, $H_0$则是相应的背景模型, NFA的内涵为在纯随机的背景噪声中出现目标结构的期望次数, 当NFA极小时可以认为目标是有效结构, 对应的数学表达形式如下:
上式中的$IP[\cdot]$为在背景模型中观测到目标事件的概率大于等于被观测事件的概率的可能性. 结合具体的视频变化检测任务, 由于由于深度特征图的像素之间存在感受野重叠(非独立性),作者通过对图像进行下采样或采用保守估计的方法(取 $c_f$ 次方根), 修正了统计独立性假设, 从而确保降虚警过程的科学性. 对于背景模型的建模, 作者采用了高斯混合模型, 对应PDF如下:
其中x为DNN提取的高位特征向量. 接下来对于每个像素i计算相应的特性$x_i$的p-value, 对应表达形式如下:
当p-value越小时说明对应像素点在背景中越罕见, 因此越有可能是真实的目标. 继而计算区域R的整体NFA, 表达形式如下:
上式中$N_{test}$为测试总数, 即图像中可能出现的所有候选区域, $\prod(p(x_i))$表示当假设各区域内的像素点独立分布时, 偶然产生的背景波动的概率, $c_f$为独立性修正因子, 代表特征的冗余程度. 通过设定阈值来判定某区域是否是真实的视频变化, 从而实现虚警区域的滤除. 结合以上思想, 作者提出的对应框架如下:
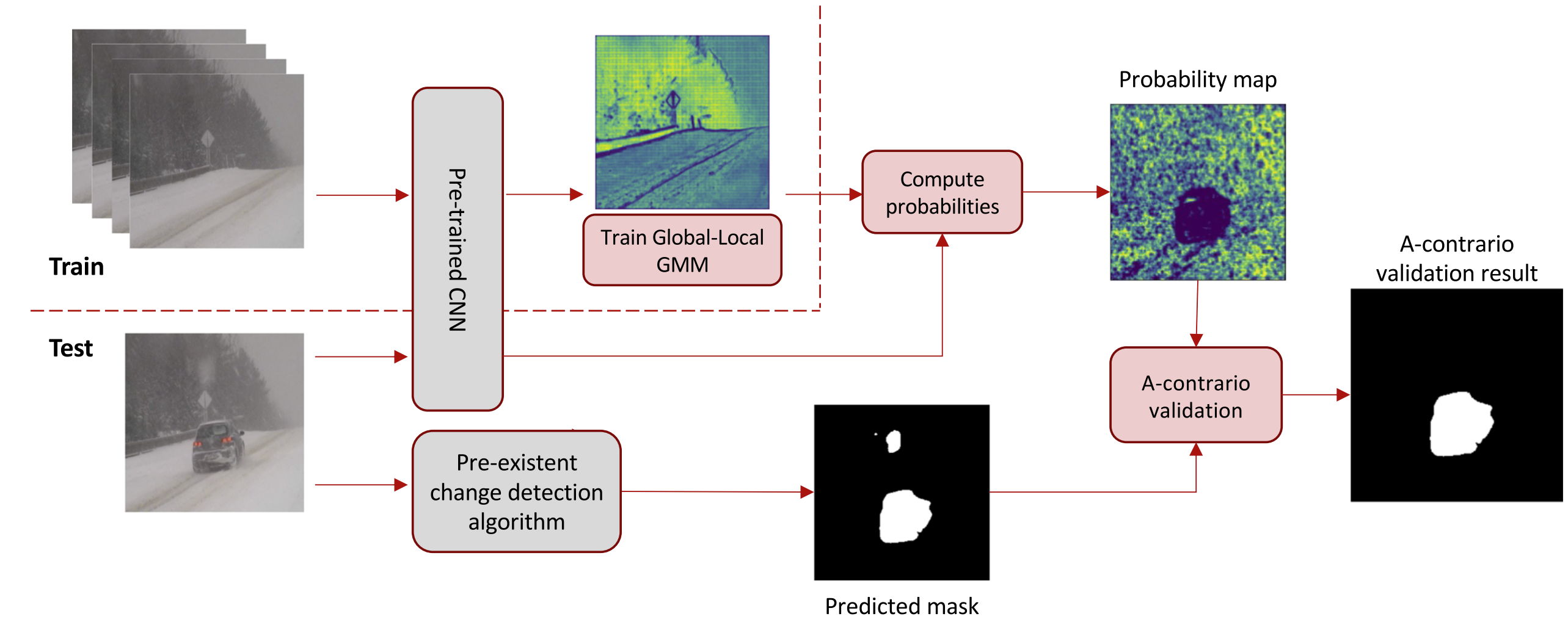
作为即插即用的模块, 作者的实验结果表明对应方法实现了鲁棒的虚警抑制效果, 对应的可视化结果如下所示:

对于虚警框的自动去除方法
论文 Dual-NMS: A Method for Autonomously Removing False Detection Boxes from Aerial Image Object Detection Results 针对航天图像存在过多虚警的问题, 针对性地提出了Dual-NMS方法, 结合预测框的密度来自动去除虚警框. 文章主要依据mAP的提高和可视化结果的比较来证明方法的有效性. 作者所提出方法的架构图和对虚警的抑制效果可视化结果如下所示:
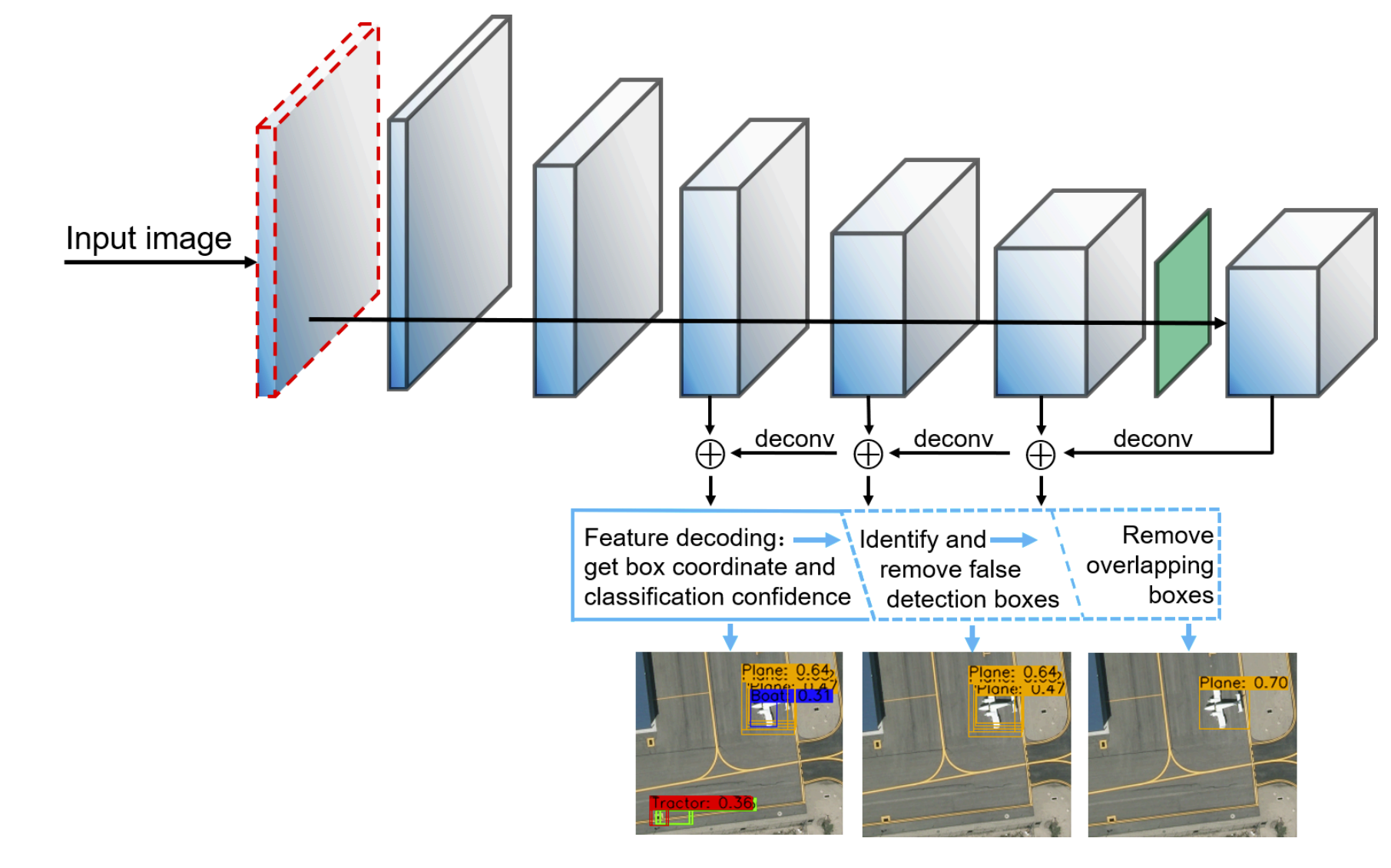
首先介绍非极大值抑制(Non-Maximum Suppression, NMS), 该方法是现代DNN目标检测模型中常用且重要的后处理方法, 其核心即为抑制冗余检测和降低虚警, NMS不是网络训练中的一部分, 而是进行检测结果中的有效候选框筛选的方法. NMS的核心计算基于两个概念, 首先置信度排序. 对于所有预测的候选框$B = \{b_1, b_2, …, b_n\}$和相应的置信度得分$S = \{s_1, s_2, …, s_n \}$, 对其按照置信度得分从大到小排序; 其次为候选框之间的交并比计算. NMS的核心操作如下:
- 初始化最终保留集合D, 设定为空集
- 对排序后的候选框列表由高到低排列: 取未被抑制的最高得分框$ b^* $, 加入D, 对所有剩余框, 计算与$b^*$的IoU, 若$IoU(b^*, b_j) \geq \tau$, 则将$b_j$从候选中抑制(即删除).
- 重复上述过程至无候选框剩余.
以上过程中的$\tau$为预设参数, 用于判定两个框是否过度重叠. NMS通过移除重复的预测结果, 保留最高得分即可有效避免重复删除, 降低了虚警的风险. 但标准的NMS被证明对于密集目标场景的处理不够理想, 同时处理效果对设定阈值过于敏感.
在论文中, 作者任务由于航拍图像(aerial images)都是从上至下拍摄的, 因此在目标检测模型中难以提取出足够数量的有效特征用于检测, 继而容易产生虚警. 虚警框大致可以分为两种: (1). 背景中没有目标的区域被误认为目标 (2). 真实目标区域被误分类.
作者所提出的改进的Dual-NMS的动机主要为真实检测框的平均密度明显高出虚警框密度, 通过定义检测框密度来将其作为区分真伪目标的关键条件. 对应的动态阈值函数表达式如下:
上式中d为当前检测框组的密度, $s_m$为最大的分类置信度, 其余参数均为作为缩放因子的超参数. 算法执行中系统计算该组内所有检测框置信度的总和, 当大于阈值时则认为包含真实目标, 进入后续的标准NMS; 当小于阈值时认为是虚警直接移除.
针对Precision指标, 文章的实验结果如下所示, 可以看出实现了理想的提升效果:
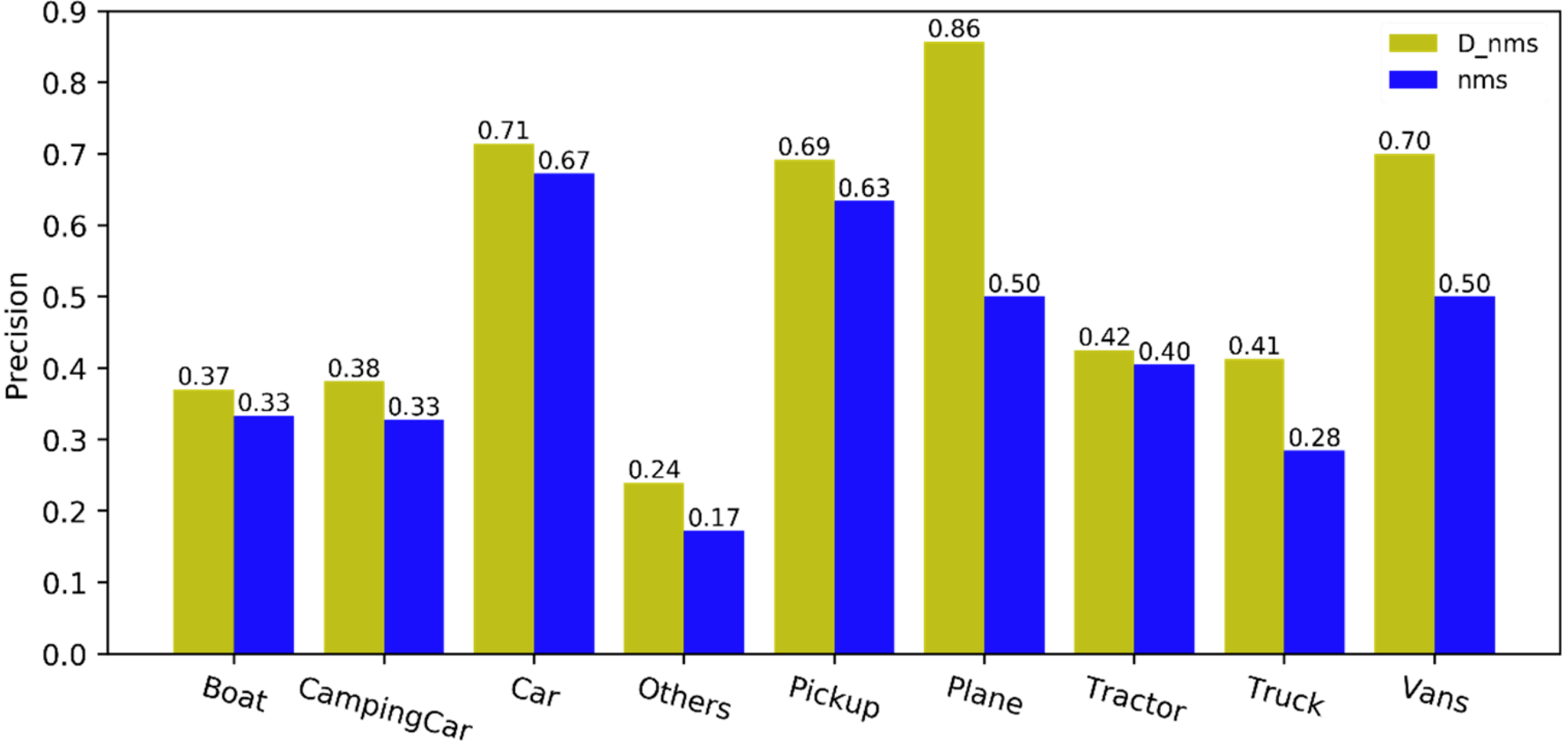
需要额外说明的是, 文章所定义的虚警框更倾向于false positive, 与SAR图像检测中出现的真实目标周围的多个预测框的场景还存在较大的差距.
总结
针对False Alarm这一关键词进行调研后初步的结论是对于目标检测任务而言, False Alarm还没有成为一种严格的研究主题(显著表现是没有针对性的评估指标)并获得广泛的关注, 同时由于NMS算法的设定以及检测模型的不断发展, False Alarm本身或许可以作为模型性能局限, 通过对mAP的提升来解决. 因为有监督模型的训练往往可以在足够数据量的前提下拟合到理想的标签分布, 当训练数据的标签质量得到保证时, 不应该存在明显的以出现大量检测框为特征的虚警现象. 但在SAR目标检测任务中确实出现了上述的情况(而在大规模光学数据集上类似问题并不显著), 因此可以首先通过实验确认这种现象的产生规律, 与对应数据以及分布的关联, 并给出合理的评估SAR目标检测任务中False Alarm问题的Evaluation Metrix.